Algorithmic Forays Part 5
|
|
ADVERTISEMENT |
Last time we met, you learned about Thompson's Construction - an algorithm for building NFAs from regular expressions. I also presented a "starter" implementation of a basic NFA class in C++. In this article, you'll see the connection between these two. I will present a complete C++ implementation of Thompson's Construction. Additionally, you will see how to represent regular expressions with parse trees, and get acquainted with the code that builds complete NFAs from these regular expressions.
Implementing Thompson's Construction
Thompson's Construction, as you probably remember (If you don't, it is a good time to skim through the previous article) tells us how to build NFAs from trivial regular expressions and then compose them into more complex NFAs. Let's start with the basics:
The simplest regular expression
The most basic regular expression is just some single character, for example a. The NFA for such a regex is:
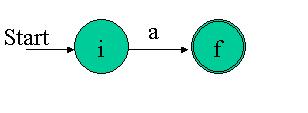
Here is the implementation:
// Builds a basic, single input NFA
//
NFA build_nfa_basic(input in)
{
NFA basic(2, 0, 1);
basic.add_trans(0, 1, in);
return basic;
}
Just to remind you about our NFA implementation: The first line of the function creates a new (with no transitions yet) NFA of size 2 (that is: with 2 states), and sets state 0 to be the initial state and state 1 to be the final state. The second line adds a transition to the NFA that says "in moves from state 0 to state 1". That's it - a simple regex, a simple construction procedure.
Note that this procedure is suited for the construction of an eps transition as well (it was presented separately in the last article's discussion of Thompson's Construction).
Some changes to the NFA class
Last article's implementation of a simple NFA class was just a starting point and we have quite a few changes to make.
First of all, we need direct access to all of the class's data. Instead of providing get and set accessors (which I personally dislike), all of the class members (size, initial, final and trans_table) have been made public.
Recall what I told you about the internal representation inside the NFA class - it's a matrix representing the transition table of a graph. For each i and j, trans_table[i][j] is the input that takes the NFA from state i to state j. It's NONE if there's no such transition (hence a lot of space is wasted - the matrix representation, while fast, is inefficient in memory).
Several new operations were added to the NFA class for our use in the NFA building functions. Their implementation can be found in nfa.cpp (one of the files in the .zip that comes with this article). For now, try to understand how they work (it's really simple stuff), later you'll see why we need them for the implementation of various Thompson Construction stages. It may be useful to have the code of nfa.cpp open in an editor, and to follow the code for the operations while reading these explanations. Here they are:
- append_empty_state - I want to append a new, empty state to the NFA. This state will have no transitions to it and no transitions from it. If this is the transition table before the appending (a sample table with size 5 - states 0 to 4):
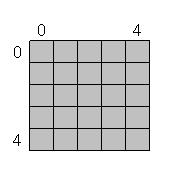
Then this is the table after the appending:

The shaded cells are the transitions of the original table (be they empty or not), and the white cells are the new table cells - containing NONE.
- shift_states - I want to rename all NFA's states, shifting them "higher" by some given number. For instance, if I have 5 states numbered 0 - 4, and I want to have the same states, just named 2 - 6, I will call shift_states(2), and will get the following table:
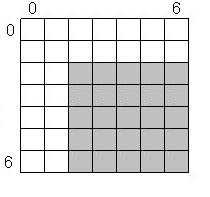
- fill_states - I want to copy the states of some other NFA into the first table cells of my NFA. For instance, if I take the shifted table from above, and fill its first two states with a new small NFA, I will get (the new NFA's states are sky blue):

Note that using fill_states after shift_states is not incidental. These two operations were created to be used together - to concatenate two NFAs. You'll see how they are employed shortly.
Now I will explain how the more complex operations of Thompson's Construction are implemented. You should understand how the operations demonstrated above work, and also have looked at their source code (a good example of our NFA's internal table manipulation). You may still lack the "feel" of why these operations are needed, but this will soon be covered. Just understand how they work, for now.
Implementing alternation: a|b
Here is the diagram of NFA alternation from the previous article:
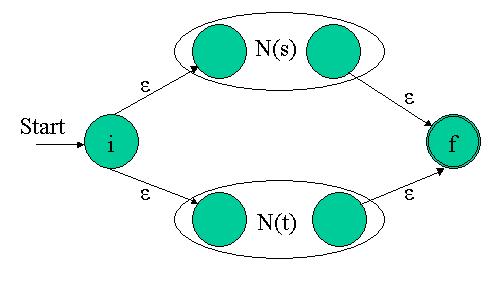
Given two NFAs, we must build another one that includes all the states of both NFAs plus additional, unified initial and final states. The function that implements this in nfa.cpp is build_nfa_alter . Take a look at its source code now - it is well commented and you should be able to follow through all the steps with little difficulty. Note the usage of the new NFA operations to complete the task. First, the NFAs states are shifted to make room for the full NFA. fill_states is used to copy the contents of nfa1 to the unified NFA. Finally, append_empty_state is used to add another state at the end - the new final state.
Implementing concatenation: ab
Here is the diagram of NFA concatenation from the previous article:

Given two NFAs, we must build another one that includes all the states of both NFAs (note that nfa1's final and nfa2's initial states are overlapping). The function that implements this in nfa.cpp is build_nfa_concat. Just as in build_nfa_alter, the new NFA operations are used to construct, step by step, a bigger NFA that contains all the needed states of the concatenation.
Implementing star: a*
Here is the diagram of the NFA for a* from the previous article:

Although the diagram looks complex, the implementation of this construction is relatively simple, as you'll see in build_nfa_star. There's no need to shift states, because no two NFAs are joined together. There's only a creation of new initial and final states, and new eps transitions added to implement the star operation.
Specialty of NFAs constructed by Thompson's Construction
You might have observed that all the NFAs constructed by Thompson's Construction have some very specific behavior. For instance, all the basic building blocks for single letters are similar, and the rest of the constructions just create new links between these states to allow for the alternation, concatenation and star operations. These NFAs are also special implementation-wise. For instance, note that in our NFA implementation, the first state is always the initial, and the last state is always final. You may have noted that this is useful in several operations.
A complete NFA construction implementation
With these operations implemented, we now have a full NFA construction implementation in nfa.cpp! For instance, the regex (a|b)*abb can be built as follows:
NFA a = build_nfa_basic('a');
NFA b = build_nfa_basic('b');
NFA alt = build_nfa_alter(a, b);
NFA str = build_nfa_star(alt);
NFA sa = build_nfa_concat(str, a);
NFA sab = build_nfa_concat(sa, b);
NFA sabb = build_nfa_concat(sab, b);
With these steps completed, sabb is the NFA representing (a|b)*abb . Note how simple it's to build NFAs this way! There's no need to specify individual transitions like we did before. In fact, it's not necessary to understand NFAs at all - just build the desired regex from its basic blocks, and that's it.
Even closer to complete automation
Though it has now become much simpler to construct NFAs from regular expressions, it's still not as automatic as we'd like it to be. One still has to explicitly specify the regex structure. A useful representation of structure is an expression tree. For example, the construction above closely reflects this tree structure:

In this tree: . is concatenation, | is alternation, and * is star. So, the regex (a|b)*abb is represented here in a tree form, just like an arithmetic expression.
Such trees in the world of parsing and compilation are called expression trees, or parse trees. For example, to implement an infix calculator (one that can calculate, for example: 3*4 + 5), the expressions are first turned into parse trees, and then these parse trees are walked to make the calculations.
Note, this is, as always, an issue of representation. We have the regex in a textual representation: (a|b)*abb and we want it in NFA representation. Now we're wondering how to turn it from one representation to the other. My solution is to use an intermediate representation - a parse tree. Going from a regex to a parse tree is similar to parsing arithmetic expressions, and going from a parse tree to a NFA will be now demonstrated, using the Thompson's Construction building blocks described in this chapter.
From a parse tree to a NFA
A parse tree in our case is just a binary tree, since no operation has more than two arguments. Concatenation and alternations have two arguments, hence their nodes in the tree have two children. Star has one argument - hence only the left child. Chars are the tree leaves. Take a good look at the tree drawn above, you'll see this very clearly.
Take a look at the file regex_parse.cpp that comes with this article. It has alot in it, but you only need to focus only on some specific things for now. First, let's look at the definition of parse_node:
typedef enum {CHR, STAR, ALTER, CONCAT} node_type;
// Parse node
//
struct parse_node
{
parse_node(node_type type_, char data_, parse_node* left_, parse_node* right_)
: type(type_), data(data_), left(left_), right(right_) {}
node_type type;
char data;
parse_node* left;
parse_node* right;
};
This is a completely normal definition of a binary tree node that contains data and some type by which it is identified. Let us ignore, for the moment, the question of how such trees are built from regexes (if you're very curious - it's all in regex_parse.cpp), and instead think about how to build NFAs from such trees. It's very straight forward since the parse tree representation is natural for regexes. Here is the code of the tree_to_nfa function from regex_parse.cpp:
NFA tree_to_nfa(parse_node* tree)
{
assert(tree);
switch (tree->type)
{
case CHR:
return build_nfa_basic(tree->data);
case ALTER:
return build_nfa_alter(tree_to_nfa(tree->left), tree_to_nfa(tree->right));
case CONCAT:
return build_nfa_concat(tree_to_nfa(tree->left), tree_to_nfa(tree->right));
case STAR:
return build_nfa_star(tree_to_nfa(tree->left));
default:
assert(0);
}
}
Not much of a rocket science, is it? The power of recursion and trees allows us to build NFAs from parse trees in just 18 lines of code...
From a regex to a parse tree
If you've already looked at regex_parse.cpp, you surely noted that it contains quite a lot of code, much more than I've show so far. This code is the construction of parse trees from actual regexes (strings like (a|b)*abb).
I really hate to do this, but I won't explain how this regex-to-tree code works. This article series is complicated enough without getting into parsing. You'll just have to believe me it works (or study the code - it's there!). As a note, the parsing technique I employ to turn regexes into parse trees is called Recursive Descent parsing. It's an exciting topic and there is plenty of information available on it, if you are interested.
We've come a long way...
Let's see what we have accomplished: we have implemented the complete process of taking regular expressions and turning them into NFAs - automatically! Our program turns the regexes into parse trees, walks these parse trees and creates NFAs from them using Thompson's Construction.
To see this in action, compile the files nfa.cpp and regex_parse.cpp together (make sure nfa.h resides in the same directory). This would be the command for those who use GCC:
g++ -o regex2nfa regex_parse.cpp nfa.cpp
regex_parse.cpp contains a small main function that takes the first argument and displays the NFA resulting from it. For instance, running:
regex2nfa "(a|b)*abb"
Displays:
This NFA has 11 states: 0 - 10 The initial state is 0 The final state is 10 Transition from 0 to 1 on input EPS Transition from 0 to 7 on input EPS Transition from 1 to 2 on input EPS Transition from 1 to 4 on input EPS Transition from 2 to 3 on input a Transition from 3 to 6 on input EPS Transition from 4 to 5 on input b Transition from 5 to 6 on input EPS Transition from 6 to 1 on input EPS Transition from 6 to 7 on input EPS Transition from 7 to 8 on input a Transition from 8 to 9 on input b Transition from 9 to 10 on input b
Which is, if you recall, the exact same NFA we dutifully crafted by hand for (a|b)*abb in the previous article. Now, we can generate it automatically!
A note about the source code
Along with this article, comes a .zip file containing all the code. It currently consists of 3 files: nfa.h, nfa.cpp and regex_parse.cpp (which contains a main() function). All the code, like all my future code for the series is in the public domain - you may do anything you wish with it. If you have any problem compiling and running it, feel free to contact me, I'll help. I'd also be quite happy to receive feedback and bug reports.
© Copyright by Eli Bendersky, 2003. All rights reserved.
Discuss this article in the forums
Date this article was posted to GameDev.net: 8/17/2004
(Note that this date does not necessarily correspond to the date the article was written)
See Also:
Featured Articles
General
© 1999-2011 Gamedev.net. All rights reserved. Terms of Use Privacy Policy
Comments? Questions? Feedback? Click here!