|
Radiosity Mapping
The theory behind radiosity mapping is that you should be able to approximate the radiosity of an entire object by precalculating the radiosity for a single point in space, and then applying it to every other point on the object. The reason that this works is because points in space that are close together all have approximately the same lighting. You can very easily see that this is true by merely looking at two points on a real-life object that are about a half inch apart. You will notice that both points have very close to the same lighting.
But what about points that are far apart from each other? Well, then you would have to calculate a different radiosity solution for each of them, because their lighting values are not similar enough. And that is one of the little quirks of this method: it can only be used on small objects. Which means that walls, floors, etc. are out of the question. The only things that this particular method will be good for are objects such as people, weapons, red markers (inside joke for those of you who read my last article), etc.
Now that we have all of that sorted out, there are still two rather large questions looming over our heads: how do we calculate and store the radiosity of a single point in space, and how do we use the single points pre-calculated radiosity to approximate the radiosity of the other points on the object?
Well, the first of those questions is rather easy to answer: a cube view. For those of you who do not know what a cube view is, I will explain. If you already know what a cube view is, then you may skip the next paragraph.
A cube view is actually a very simple concept. It is merely six renderings of the scene from a single point in space. One of those renderings is rendered with the view looking up. Another of the renderings is rendered from the view looking down. Another is left, another is right, another is forward, and another is backward. When all of the six renderings are put together, so that their edges line up, they form a cube. And that cube just happens to be a full 360-degree view of the entire scene from a single point in 3D space! Also, each of the views must be rendered with a fov (field of view) of 90 degrees. Otherwise, if the fov is greater than 90, the views will overlap in what they render, or if it is less, they will have gaps between them. To get a fov of 90 degrees, use the following formula for perspective calculation: xo = (x / z) * one_half_screen_res where xo is the x that is output. Also, use the same formula, except for the y value. "one_half_screen_res" is one half of a single dimension of the screen resolution. For instance, if you were to have a screen res of 256x256 for each side of the cube view, then one_half_screen_res would be equal to 128 (which is 256 / 2). Another thing you must make certain of is that each side has a resolution of equal width and height (i.e. 256 by 256 is ok, but 320 by 240 is not). If it is not, then it will not be a cube view, and the images will not "fit" correctly.
So, the way you store the radiosity information of the single point in space, is you render a cube view from that point. Of course, that raises the question of what point in space we should render the cube view from. Well, that is actually quite simple: the center of the object. And, to get the center of the object, all you need to do is find the average position of all of its vertices. And, depending on the number of vertices in your object, it may be faster to precalculate that point, or calculate it on the fly. The difference between the two is that if you precalculated it, you would have to rotate it and translate it along with the rest of the object. Considering how many polygons are typically in 3D models for games, I'd say that more often than not, it would be faster to precalculate the point, and rotate/translate it with the rest of the object.
One other thing that I'd hope is a given (but people often surprise me), is that you should ignore the object that your pre-calculating the radiosity for when you render the cube view. Otherwise, you will just get the inside of your object when you render the cube view.
So, now you've got this cube view for your object. But what do you do with it? Well, this is the hard part.
The basic idea behind it is that we want to treat every pixel of the cube view as if it were a light source, because the entire point of radiosity is that objects contribute light to other objects. As we know, the light contribution of a light source fades with both distance, and with angle. So to deal with the first one, we keep the z-values of each pixel, and lower it's contribution to the light based on how far away it is, right? Wrong. The light fade is already taken into account, because the further away the object is from the point in space, the smaller it is on the cube view (because of perspective), which means that it has less global contribution. So, guess what! We don't have to do anything more, as far as fading with distance goes.
But there is still the problem of the angle. In theory, one thing you could do would be to draw a vector to each pixel of the cube view from the center of the cube (since that's where the point in question is assumed to be). You could then use the dot product between those vectors and the surface normal to find the contribution of each pixel. However, in practice that's going to be much too slow. Even if you made all of the vectors in advance, you would still have the problem of the dot product (in fact, the dot product is the main problem).
Well, since dealing in 3D space is too slow, why don't we deal in 2D space? The only problem is: how? How could we calculate the fade from angle in 2D space? It just so happens that we have the perfect tools for this: skipping pixels, and averaging.
Now, I'm certain that all of you are thinking "He's insane," or at least, "What is he talking about?"
First, I will tell you what to do, and then I will tell you why it works.
First, what we must do is to create a polar pattern where, for every distance from the center, there are four pixels selected. Of course, when I say a "polar" pattern, I don't mean that it should be represented in a polar method; you should still store it as pixels. I merely mean that you should make the pattern by assuming circles coming from the center of the image.
A very basic pattern of the type I am talking about would be the following:
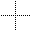
Note that in this example, black pixels are the ones that are to be sampled, and white ones are the pixels to be ignored.
As you can see, there are four sampled pixels for each distance away from the center of the image. However, it is very localized sampling. Or rather, it only samples from the four off shoots from the center, which means that objects that are only in the quadrants will not be sampled (which is not good). Therefore, we must disperse the points more evenly, so that they cover more area, while still maintaining the four-pixels-per-distance rule. An example of a more evenly dispersed pattern would be this:
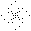
Obviously, that is not the only dispersed pattern that you could use. In fact, it's probably not even the best one, seeing as it has a consistent shape to it. It would probably be best to have the program randomly generate a pattern when it starts from the rules I described above, and then use that pattern for the rest of the program running time; that would create a much more well-dispersed sampling pattern.
Of course, this entire pattern thing brings up a rather strange question: what do we do with the pattern? Well, what we do is we find the pixel of the cube view that the surface normal of the given vertex intersects. We then assume that as being the center of the place where the pattern is to be mapped. Then, wherever there are black pixels mapped onto the cube view, we sample the underlying pixel of the cube view. Once we have all of those pixels, we average the colors of all of the sampled pixels together. And, guess what? We now have a base radiosity lighting value!
But how do we apply the pattern to the cube view to determine the pixels to sample? We can't just map it on, because if we do, it will have missing sections (from the cube view's corners), right? Well, yes, it would have missing sections from the corners of the cube, but that doesn't mean that we can't use it! Think about it, the ratio of 4 pixels per circle will only be minimally changed by the corners, because we generated a random pattern. So, we can, in fact, merely map it onto the cube view, and merely ignore the pixels of the pattern that don't actually end up on part of the cube view. Of course, you've got to figure out which way the pattern is to be mapped across the edges, which is actually quite simple: take which ever face the center of the pattern is on (i.e. the intersection of the vertex normal), and take the four sides which share edges with it. You then "set it up" in the following way:

Of course, in practice you're not going to actually set them up like that on a separate image, your merely going to treat the separate sides of the cube view as if they lined up like that.
But how does the pattern sampling approximate the fade off with angle? Well, it's actually quite simple, if each circle has only four pixels, then all circles have equal contribution. And, since the outer circles are bigger then the ones nearer to the center, they have a much smaller size to contribution ratio!
Also, the pattern should have twice the dimensions of any given side of the cube view. In other words, if you had a cube view where each side was a 16x16 image, then the pattern would need to be 32x32. The reason for this is that that way the pattern will be sampling from approximately half of the cube, which amounts to the same thing as 180 degrees. That means that your surface won't be getting light from things that are supposed to be behind it! And if you were to have a smaller resolution, it wouldn't get the full 180 degrees, so your sampling would be too limited, and it wouldn't look right.
The last and final step of radiosity mapping is your application of it to the 3d model. There are two different ways to go about doing this. The first is to find the radiosity base lighting values for each vertex in the model, and then use gouroud shading, and the second is to use the vertex surface normal intersections with the cube as UV coordinates, and the map the entire cube view onto the model. I would suggest the gouroud shading method, because doing true full texture mapping of it would be extremely time consuming, since you'd have to do the pattern filter for ever single pixel on the screen that the object takes up.
Anyway, when you have the radiosity lighting value for a vertex, you then add that lighting value (not averaging!) to the light values obtained from the normal light source lighting algorithms.
A few last words of recommendation for if/when anyone implements this. First, you do not need to have a high resolution cube view. In fact, it would be just fine to have each side of the cube view be 16x16, or even 8x8. Think about it, if each side is 16x16, then your going to have 256 pixels for each side, which is plenty! Of course, with 8x8, you're going to have a bit of degradation in the radiosity quality (only 64 pixels a side), but it probably won't make that much of a difference.
Second, you might want to check to see if there would be any significant change in the objects radiosity before you decide to update it (i.e. selective updating of the cube views). That would be done by checking to see if the object it self has moved any great deal, and if any other dynamic objects or light sources in the vicinity have moved significantly.
|
