|
Binary Search Trees
The most popular variation of the Binary Tree is the Binary Search Tree (BST). BSTs are used to quickly and efficiently search for an item in a collection. Say, for example, that you had a linked list of 1000 items, and you wanted to find if a single item exists within the list. You would be required to linearly look at every node starting from the beginning until you found it. If you're lucky, you might find it at the beginning of the list. However, it might also be at the end of the list, which means that you must search every item before it. This might not seem like such a big problem, especially nowadays with our super fast computers, but imagine if the list was much larger, and the search was repeated many times. Such searches frequently happen on web servers and huge databases, which makes the need for a much faster searching technique much more apparent. Binary Search Trees aim to Divide and Conquer the data, reducing the search time of the collection and making it several times faster than any linear sequential search.
Binary Search Tree Interface
Here is the general interface for a binary search tree. Notice that the BST class encapsulates binary tree nodes, rather than inherits them. This makes it easier to deal with a BST as one solid class, which handles insertions, searches and removals automatically for you.
// ----------------------------------------------------------------
// Name: BinarySearchTree::BinarySearchTree
// Description: Default Constructor. an empty BST
// Arguments: - compare: A function which compares two
// dataTypes and returns -1 if the left
// is "less than" the right, 0 if they
// are equal, and 1 if the left is
// "greater than" the right.
// Return Value: None.
// ----------------------------------------------------------------
BinarySearchTree( int (*compare)(dataType& left, dataType& right) )
// ----------------------------------------------------------------
// Name: BinarySearchTree::~BinarySearchTree
// Description: Destructor.
// Arguments: None.
// Return Value: None.
// ----------------------------------------------------------------
~BinarySearchTree()
// ----------------------------------------------------------------
// Name: BinarySearchTree::insert
// Description: Inserts data into the BST
// Arguments: - p_data: data to insert
// Return Value: None.
// ----------------------------------------------------------------
void insert( dataType p_data )
// ----------------------------------------------------------------
// Name: BinarySearchTree::has
// Description: finds the given data in the BST
// Arguments: - p_data: data to search for
// Return Value: true or false
// ----------------------------------------------------------------
bool has( dataType p_data )
// ----------------------------------------------------------------
// Name: BinarySearchTree::get
// Description: finds the specified data within the tree and
// returns a pointer to it.
// Arguments: - p_data: data to search for
// Return Value: pointer to data, or 0 if not found.
// ----------------------------------------------------------------
dataType* get( dataType p_data )
// ----------------------------------------------------------------
// Name: BinarySearchTree::remove
// Description: finds and removes data within the tree.
// Arguments: - p_data: data to find and remove
// Return Value: True if remove was successful, false if not.
// ----------------------------------------------------------------
bool remove( dataType p_data )
// ----------------------------------------------------------------
// Name: BinarySearchTree::count
// Description: returns the count of items within the tree
// Arguments: None.
// Return Value: the number of items.
// ----------------------------------------------------------------
inline int count()
// ----------------------------------------------------------------
// Name: BinarySearchTree::depth
// Description: returns the depth of the root node
// Arguments: None.
// Return Value: depth of the root node.
// ----------------------------------------------------------------
inline int depth()
// ----------------------------------------------------------------
// Name: BinarySearchTree::inorder
// Description: processes the BST using an inorder traversal.
// Arguments: - process: A function which takes a reference
// to a dataType and performs an
// operation on it.
// Return Value: None.
// ----------------------------------------------------------------
inline void inorder( void (*process)(dataType& item) )
// ----------------------------------------------------------------
// Name: BinarySearchTree::preorder
// Description: processes the BST using a preorder traversal.
// Arguments: - process: A function which takes a reference
// to a dataType and performs an
// operation on it.
// Return Value: None.
// ----------------------------------------------------------------
inline void preorder( void (*process)(dataType& item) )
protected:
// ----------------------------------------------------------------
// Name: BinarySearchTree::find
// Description: finds a piece of data in the tree and returns
// a pointer to the node which contains a match,
// or 0 if no match is found.
// Arguments: - p_data: data to find
// Return Value: pointer to node which contains data, or 0.
// ----------------------------------------------------------------
node* find( dataType p_data )
// ----------------------------------------------------------------
// Name: BinarySearchTree::removeNotFull
// Description: removes a node from the tree which has only one
// or no children.
// Arguments: - x: pointer to the node to remove
// Return Value: None.
// ----------------------------------------------------------------
void removeNotFull( node* x )
// ----------------------------------------------------------------
// Name: BinarySearchTree::findLargestNode
// Description: finds the largest node in a subtree
// Arguments: - start: pointer to the node to start at
// Return Value: pointer to the largest node
// ----------------------------------------------------------------
node* findLargestNode( node* start )
// ----------------------------------------------------------------
// Name: BinarySearchTree::removeFull
// Description: removes a node from the tree which has two
// children
// Arguments: - x: pointer to the node to remove
// Return Value: None.
// ----------------------------------------------------------------
void removeFull( node* x )
When constructing a BinarySearchTree, the constructor requires you to pass in a pointer to a comparison function. This function will be kept by the BST and invoked whenever the client inserts, searches for, or removes data. I have not allowed the client to modify the comparison function for a BST, simply because changing the comparison will break the BST (see the section on BST validity below). The comparison works just like the standard C strcmp(), it takes two parameters, and compares them. If the left is less than the right then it returns a negative value, If the left is equal to the right it returns 0, and if the left is greater than the right it returns a positive value. The actual meaning of the values are not important to the BST, it only cares if the value is 0, negative, or positive.
The basic operations are: insert, has, get, and remove. The algorithms for these will be discussed below. Along with these, there is a status method, count, which returns the current item count of the container, and inorder, which provides traversing capabilities to the BST by using an inorder recursive traversal, as described above. The preorder function is provided because the code prints out braces surrounding the children of each node, and gives a textual representation of the binary tree, allowing the client to see how the tree is actually constructed. The last four functions are all protected helper functions, and their usage and algorithms are also discussed below.
Validity of Binary Search Trees
The one rule that must always be followed for every node in a BST is this:
- the data element in the left subtree must be less than the value in the current node.
- the data element in the right subtree must be greater than the value in the current node.
If this rule applies to every node in a binary tree, then it is considered a valid Binary Search Tree. This is why changing the comparison function of the tree will break the tree; data to the left may not be less than data in the current node, etc.
Inserting Data
Inserting data into a binary search tree is a somewhat easy thing to do. The algorithm must follow the validity rules of a BST as stated above, and thus allows the client to insert data into the BST without being required to manually find the appropriate position. This is the main reason I chose to hide the underlying architecture of the binary tree and abstract it into a BST class. This is the general recursive algorithm for inserting data into a binary search tree node in pseudocode:
insert( dataType newData )
if( newData < data )
if( left != 0 )
left.insert( newData );
else
left = new node( newData );
else
if( right != 0 )
right.insert( newData );
else
right = new node( newData );
end insert
This routine follows the rules of a BST, and inserts the data to the left if it is less than the current data, and to the right if it is greater than the current data. The astute readers among you may have noticed something strange about the above: it breaks the second BST insertion rule just a tiny bit. If the new data is equal to the data already in the node, the algorithm inserts it to the right. Whether or not this is proper procedure, Ill leave to the experts to decide. The benefit of this is that you can insert data and not have to worry about throwing an exception or returning an error value, but inserting data twice into a binary search tree does not make too much sense, because the search algorithm will never find subsequent instances of the data, unless the first instance is removed. Actual implementation, as always, is completely up to your needs.
One more important note about the above algorithm: While the provided algorithm is recursive, it doesn't need to be. Do you remember what I said in the first article, when I explained how recursion is great for implicitly keeping track of paths followed when traversing a tree? The insertion algorithm has no need to keep track of the path it travels, because once the new data is inserted, the algorithm can just stop execution immediately. Ive re-written the algorithm to work without recursion:
void insert( dataType p_data )
{
node* current = m_root;
if( m_root == 0 )
m_root = new node( p_data );
else
{
while( current != 0 )
{
if( m_compare( p_data, current->m_data ) < 0 )
{
if( current->m_left == 0 )
{
current->m_left = new node( p_data );
current->m_left->m_parent = current;
current = 0;
}
else
current = current->m_left;
}
else
{
if( current->m_right == 0 )
{
current->m_right = new node( p_data );
current->m_right->m_parent = current;
current = 0;
}
else
current = current->m_right;
}
}
}
m_count++;
}
Notice how the iterative routine is more complex, but gets the job done quicker because it doesnt need to travel back up the call stack after the node is actually inserted. Another important fact to note is that the node class needs to be modified to use the recursive function, while the iterative solution is best implemented as an external algorithm to the binary tree node. Since the BST class composes (as opposed to inheriting them) binary tree nodes, rather than modify the node class, the iterative solution is used instead in my provided code.
Building Binary Search Trees (examples)
Let's construct a few BSTs, shall we? Let's create a binary search tree with the data set: 50, 60, 40, 30, 20, 45, 65. (Diagram 1):
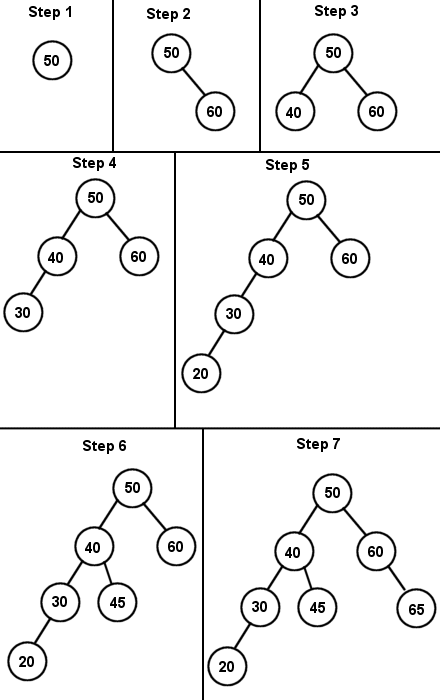
First, we start off with an empty tree, so 50 becomes the root node. We then insert 60, which is higher than 50, so we place it to the right of the root. In step 3, 40 is less than 50, so it goes to the left of the root. Since 30 is also less then 50, we try to insert it to the left of 50, but notice there is already a node there. So we go down one level and compare it to 40, and since 30 is less than 40 also, it goes to the left of that as well. In step 5, 20 goes to the left of 30, just like in step 4. In step 6, we insert 45. Since it is less than 50, it goes to the left of the root, but it is greater than 40, so we put it to the right of 40. Lastly, in step 7 we insert 65 to the right of 60. Note that this tree is considered height balanced.
Let's try another example. Insert 10, 20, 30, 40, and 50 into a new BST (Diagram 2):
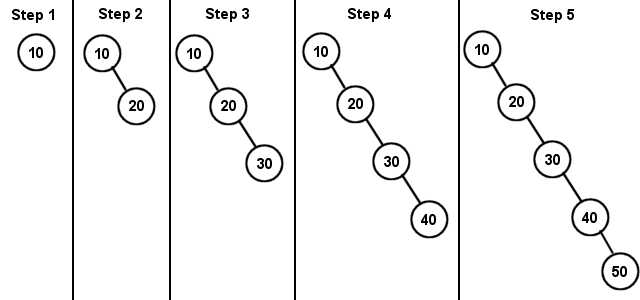
Since every node is greater than the last, they all get added to the rightmost part of the tree. Notice what kind of structure this looks like: a linked list. A Binary Search Tree that doesn't branch is very inefficient for searching. It is not height balanced at all. We'll see how to optimize this kind of tree later on using AVL trees.
Finding Data In a Binary Search Tree
Now we get to the most important part of a BST: finding data within the tree (Really, whats the point of a BST if you don't look for the data inside of it?). I am glad to say that finding data in a BST is very similar to inserting data. This also is best implemented as an iterative solution, since the algorithm has no need to travel back up the tree. I wont even bother showing the recursive solution. The general algorithm for finding data is:
node* find( dataType p_data )
{
node* current = m_root;
int temp;
while( current != 0 )
{
temp = m_compare( p_data, current->m_data );
if( temp == 0 )
return current;
if( temp < 0 )
current = current->m_left;
else
current = current->m_right;
}
return 0;
}
This algorithm shows the immense power of using a BST. Every time you compare a node and go down one level, the data left to search through is potentially halved. Divide and conquer indeed. I say potentially because the number of data items is only halved when the tree is optimal, i.e. balanced. For our second BST building exercise, Diagram 2, there is absolutely no benefit of using the BST structure for searching. Let's look at Diagram 1, again. This time we want to find out if there is data within the tree. We'll look to see if it contains 45, 10, and 50.
Steps taken to search for 45:
- 45 is less than 50, so go down to the left
- 45 is greater than 40, so go down to the right
- 45 equals 45, so we found the node, return the node.
Steps taken to search for 10:
- 10 is less than 50, so go down to the left
- 10 is less than 40, so go down to the left
- 10 is less than 30, so go down to the left
- 10 is less than 20, but 20 has no left node, return 0.
Steps taken to search for 50:
- 50 equals 50, return the node.
The maximum number of comparisons needed to find any data in this tree is 4. Incidentally, a 4 level BST can contain a maximum of 15 data elements, and the log of 15 is 4 (actually its 3.9, but since we are dealing with discrete numbers, we need to take the ceiling of the function, and always round up if the number isnt whole). Thus, we can double the number of elements in the tree to 31, but the number of comparisons required to find data in the tree only increases by 1, making 5 the maximum number of comparisons required by a balanced BST with 32 elements. This is why the optimal search time for a BST is considered O(log n).
However, there is one catch: the search algorithm for a binary search tree is actually considered O(n). How can this be? Remember, Big-O models the worst-case scenario of the algorithm, and if the tree looks like Diagram 2 above, then it is no more efficient than a linear search through a linked list. The AVL trees discussed in the next tutorial will remedy the situation.
Removing a node in a Binary Search Tree
In the general tree, we saw that removing a node from the tree also recursively removes all of its children, because it was assumed that the children were inherently related to the parent, and thus could not exist in the tree without the parent. A binary search tree is different, however, because of the way data is inserted. The user of the tree has no say in how the data is actually arranged within the tree, so it doesnt make any sense for the tree to remove all the children of a single node when the user just wants to remove one data element from the tree. Thus, there is a special algorithm used to remove nodes from a binary search tree. The algorithm takes into account that the overall ordering of the tree needs to be maintained, and only manipulates pointers so that the removal is made quickly.
There are two cases when removing a node (call this node x) from a binary search tree:
- x has either one or no children.
- x has two children.
Case I: zero or one children
The first is the easiest to complete: the parent of x just needs to be told to point to the only valid child of x, or 0 if x has no children.
void removeNotFull( node* x )
{
// find the valid child, or remain null if there
// are no children.
node* child = 0;
if( x->m_left != 0 )
child = x->m_left;
if( x->m_right != 0 )
child = x->m_right;
if( x->isRoot() )
{
m_root = child;
}
else
{
if( x->isLeft() )
x->m_parent->m_left = child;
else
x->m_parent->m_right = child;
}
// reset the parent node of the child, if it exists.
if( child != 0 )
child->m_parent = x->m_parent;
x->m_left = 0;
x->m_right = 0;
delete x;
}
The function first finds out which child of x is valid. If neither of xs children are valid, then the child variable remains null. Next, the algorithm determines what kind of node x is, whether it is the root, a left child, or a right child. Then the parent or the root is told to point to the determined child node. Lastly, xs child pointers are cleared and it is deleted. It is imperative that the child pointers are cleared, because we are using a recursive node for this implementation which deletes all of its child nodes when deleted itself, and if its child pointers are not cleared, it will end up deleting nodes which should not be deleted.
Case II: two children
The second case is more difficult, because there are two nodes in the way, instead of just one. Now we must find a way to move up a node in one of the branches, so that the tree retains its ordering, and the node has only one child. Luckily for us, both the largest node and the smallest node in any given subtree are guaranteed to have only one or zero children. This is because of the BST validity rules: if the smallest node in a subtree had a left child, the child is larger than the smallest node, thus breaking the first BST rule. The same thing can be proved for the largest node in a subtree. Therefore, we have a choice, whether to move up the largest node from the left sub-tree to replace x, or the smallest node from the right sub-tree. For simplicity, I have elected to always choose the largest node in the left (call this node l), but take note that more optimized implementations may choose to determine which sub-tree is larger and then move the appropriate node up from there, in an effort to preserve the balancing of a tree.
The algorithm for finding the largest node in any given subtree is simple: travel down every right child of every node until you reach an empty right child. The first node with an empty right child will be the largest in the subtree. Here is the algorithm:
node* findLargestNode( node* start )
{
node* l = start;
// travel the path all the way down to the right.
// the rightmost node is the largest in the subtree.
while( l->m_right != 0 )
{
l = l->m_right;
}
return l;
}
There are two sub-cases when moving up the largest node in the left subtree:
- l is to the immediate left of x.
- l is hidden deeper in the left subtree of x.
In case 1, the parent of x needs to be changed to point directly to l. We can do this because we know that the largest node in any subtree will have no right children.
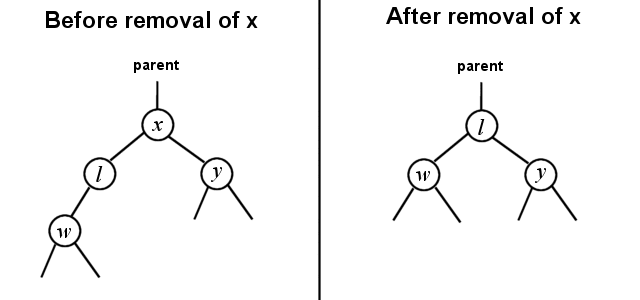
In case 2, the parent of x needs to be changed to point to l also, but there is a bit more work involved. We know that l is a right child of some other node now, and we also know that l has no right child, but l might have a left child. The solution is resolved exactly as if we were removing l from the tree (using a slightly modified removeNotFull() algorithm), by making the parent of ls right pointer point to the left child of l. Then ls left child needs to be changed to point to the left child of x, and ls right child needs to be changed to point to the right child of x.
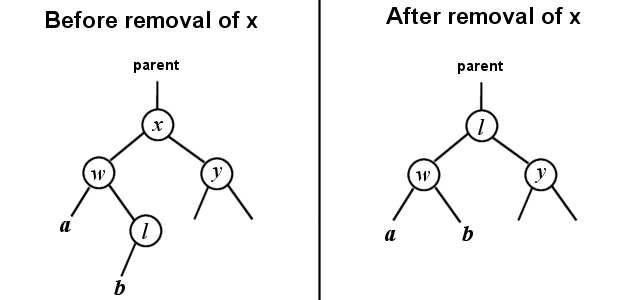
Nodes a and b do not necessarily exist, they could be null, or they could be valid, the algorithm works either way.
void removeFull( node* x )
{
node* l = findLargestNode( x->m_left );
// There are two cases:
if( x->m_left == l )
{
// The largest node is immediately to the left
// of the node to remove, so bypass x, and transfer
// x's right child.
l->m_right = x->m_right;
l->m_right->m_parent = l;
}
else
{
// the largest node is somewhere deeper in the tree.
// shortened removeNotFull algorithm <G>:
// (notice how many assumptions can be made)
l->m_parent->m_right = l->m_left;
if( l->m_left != 0 )
l->m_left->m_parent = l->m_parent;
// now replace x with l.
l->m_left = x->m_left;
l->m_left->m_parent = l;
l->m_right = x->m_right;
l->m_right->m_parent = l;
}
if( x->isRoot() )
m_root = l;
else
{
if( x->isLeft() )
x->m_parent->m_left = l;
else
x->m_parent->m_right = l;
}
l->m_parent = x->m_parent;
x->m_left = 0;
x->m_right = 0;
delete x;
}
Removing Nodes from a Binary Search Tree (examples)
Now, were going to try removing some nodes from the tree. Well take the same diagram 1 that we built earlier, and remove 20, 60, and 50, in that order.
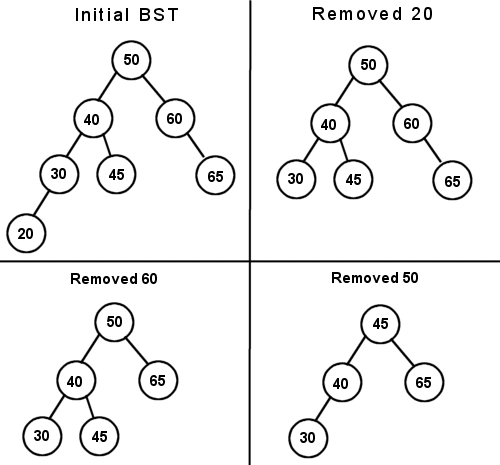
20 is easy to remove, as it is a leaf node. 30 is simply notified that it no longer has a left child. Removing 60 uses the same algorithm. Since it has only one child, 50s right pointer is changed to bypass 60 and point directly to 65. Removing 50 is a bit more difficult, as it has two children. We need to find a node that has only one child and move it upwards. Since the algorithm we are using just finds the largest node in the left subtree, it decides to move 45 up into 50s place.
Final note on the remove algorithm
I made this algorithm up myself. It is an extensive modification of the existing algorithms that I have found, which have all turned out to be inadequate. Most algorithms I have found use three or four cases, and separate the one or no child cases into separate algorithms. I condensed them into one algorithm, because they do the same thing. One algorithm I found even goes as far as finding the largest node in the left branch, whenever x has a left child, even if it doesnt have a right child. This is clearly wasteful, because it could simply move the left child up one level, without having to search for the largest child in the subtree. Regardless, I am one hundred percent certain that the algorithm I have provided is flawless, I have done extensive testing, and formally written out every case possible on paper and solved them.
Sorting Data with a Binary Search Tree
One thing that Ive always found cool about a binary search tree is that is automatically sorts data as it is inserted, with an algorithm whose optimal complexity is. If you look at what the actual tree looks like, it may not seem very sorted at first, but try tracing through an in-order traversal by hand. Youll see that it actually traverses every item in the tree in order! Hence the name, in-order traversal. Try it on this tree:
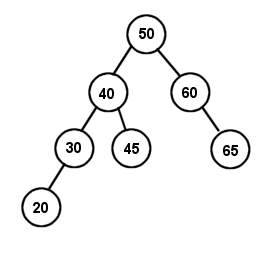
An in-order traversal results in: 20, 30, 40, 45, 50, 60, 65. The optimal sorting time of a BST sort is approximately O(n log n), with a worst case of O(n2), which is in the same area of a quicksort and a heap sort, two of the most efficient sorts that exist.

Next : Non-recursive binary tree techniques
|
