|
Optional: Non-recursive Binary Tree techniques
I consider this section optional, and have included it only for completeness. It discusses ways in which binary tree traversals can be modified to make them iterative rather than recursive. A recent trend in the computer gaming industry is portability. While it is true that the Nintendo GameBoy is over ten years old, the market somewhat dried up within the past three years, but it has recently been warming up again. With powerful small devices such as the Cybiko becoming popular, handheld PDAs appearing everywhere, the not-so-distant release of the GameBoy Advance, and a thriving community of graphing calculator programmers, it is not surprising that portable games are also becoming popular. However, the public has been spoiled lately by all the 3d games, that a handheld game in todays market really needs to fill some large shoes. Simple little games are not going to cut it anymore, and thus algorithms and data structures used to efficiently store huge worlds need to be created. This is where the iterative solutions come into play: All of these devices have horribly small stacks (compared to their big brothers, the PCs and game consoles), and will crash after a small number of function calls.
Let's get real for a moment though, shall we? If a handheld system has a small stack, it most likely has a small memory also. This makes binary trees a somewhat inappropriate choice of a data structure, simply because of the many links that need to be maintained, and waste memory. This is exactly why I consider this portion optional: I have not yet found a real-world use for non-recursive tree iterations that warrants the overhead of an iterative routine. The very fact that they can be made iterative, however, is a nice example of how every recursive algorithm can be made iterative, something Discrete Mathematicians like figuring out. <G>
Threaded Trees
Note that the term thread here has no relation to the name commonly given to computer processes. Thread, in this case, simply refers to a sewing analogy; essentially, every empty child pointer in the tree keeps a thread attached to the next node in an in-order traversal routine. I have actually implemented one of these before, as a project for school, and let me say this: I have absolutely no desire to ever work with one of these structures, ever again. While the theory behind it is simple, actual implementation is quite difficult, especially for the remove algorithm, which took 7 pages of code alone. Heres a diagram:
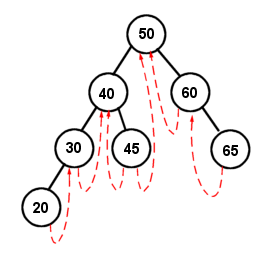
Basically, the idea of a thread (the red lines) is to utilize the unused space of empty child pointers. So the thread pointers are exactly like normal child pointers, but they require a boolean to determine if the link is a thread or a child link. So each thread points to the next or previous node in an in-order traversal. Left threads point to the previous node, right threads point to the net node. Traversing this kind of tree requires some checks, and goes like this:
inOrder( process() )
current = root;
while( current.left != 0 )
current = current.left
while( current != 0 )
process( current )
if( current.hasRightThread() )
current = current.right
else
current = current.right
while( !current.hasLeftThread )
current = current.left
end while
end if
end while
I Just want to finish up by saying that while threads are a pretty cool idea, I honestly dont think that the extra effort needed to rearrange the threads are worth the effort unless recursion as a solution is to be avoided at all costs.
Another in-order traversal method
Here is another technique for iteratively tracing through an in-order traversal. The basic idea operates on a few assumptions:
- When you are processing any node, the left child has already been processed, and the right child has not
- If the node being processed has no right child, and the current node is a left child, then the node above it has not been processed (think about it for a minute).
- If the node being processed has no right child, but the current node is a right child, then you need to travel up until you find a left child, then go up one more level.
It takes a fair amount of checking to remove the recursion, but if you cannot use recursion, the method is worth the extra effort:
inline void inorderIterative( void (*process)(dataType& item) )
{
node* current;
current = m_root;
if( current != 0 )
{
while( current->m_left != 0 )
current = current->m_left;
while(1)
{
process( current->m_data );
if( current->m_right != 0 )
{
current = current->m_right;
while( current->m_left != 0 )
current = current->m_left;
}
else
{
if( current->isLeft() )
{
current = current->m_parent;
}
else
{
while( current->isRight() )
current = current->m_parent;
if( current->isRoot() )
return;
current = current->m_parent;
}
}
}
}
}
This assumes that the root node has a parent pointer of 0. And there you have it.
Conclusion
Well, I just looked at the page count, and I am up to 26 pages without the diagrams, which is somewhat larger than the first article. I did mean to get to three other types of trees in this article, but I think its better to put them in the next article, along with another type. The four I hope to discuss are:
- AVL Trees: These help the balancing problem that BSTs have when data is inserted in a somewhat ordered fashion.
- Splay Trees: These are BSTs which dynamically move data up to the top of the tree based on how frequently it is accessed. These help optimize searches on data sets that have locality-of-reference.
- Heaps: Another sorted tree structure, used in efficient priority queue implementations.
- Huffman Trees: Simple, yet elegant data compression.
Better to let all this sink in, before you go on to learning even more. Im sorry I overestimated what I could reasonably fit into one article, but I promise Ill get started on it immediately. So, the previously planned topics for Article #3 are now pushed back to a fourth article. Until next time!
|
