Enhancing Stenciled Shadow Volumes
|
|
ADVERTISEMENT |
Introduction
In order to use the shadow volume technique described in "Practical and Robust Stenciled Shadow Volumes for Hardware-Accelerated Rendering" (found at developer.nvidia.com), you have to render the scene geometry n+1 times, n being the number of lights, plus the shadow volumes for each light. What follows is that the GPU transforms every vertex position n+1 times exactly the same way, which is obviously not a good situation, especially if indexed palette skinning or tweening is applied, too. This is only one example that reusing transformed vertex data will prove to be a big advantage. A solution might be to store the data in a floating-point surface, which I'll explain in detail now.
How it works …
We split the vertex data into at least 2 vertex buffers: the first can remain statically in local video memory and contains the untransformed vertex position and an "id", the second the transformed position plus additional data like diffuse color or texture coordinates. In the first rendering pass a floating-point surface is set as our rendering target, a (hardware) vertex shader transforms the positions and passes them via a texture register to a pixel shader which simply copies them to the output color register. The surface is a single row of NumVert Pixels (NumVert being the number of vertices) and has 128 bits per pixel, 32 bits each channel (red, green, blue, alpha), but we'll only take advantage of the first 3 to save the x-, y- and z-values, respectively, of the transformed positions. One might object that the w-coordinate is missing; the reason is, that, in order to save bandwidth, a homogeneous divide is done by the mentioned vertex shader, and consequently the standard w-value 1 is always fitting. Every vertex maps to one pixel of the surface, the first vertex in the stream to the first pixel (from left), the second to the second pixel etc. Here our "id" comes in: it's a special x-value that's emitted by the above vertex shader as the output vertex position (red points in the picture below; this has nothing to do with the transformed position data we want to reuse). The picture illustrates how the mapping is done in case we have 4 vertices. The grey rectangle is the front side of the clipping volume and the yellow, green, light blue and dark blue fields are the pixels of our rendering target.
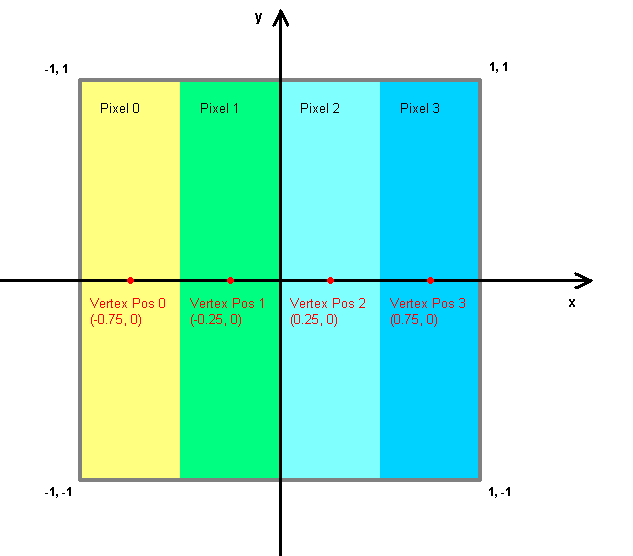
The ids are -0.75, -0.25, 0.25 and 0.75. Each id is calculated by the following formula, i being the index into the vertex stream of the corresponding vertex:
id = (2 * i + 1) / NumVert - 1
Now that the surface has been "filled", we set the rendering target back to normal, copy the surface data in some way to the second vertex stream and do as many rendering passes as we want, using the transformed vertex data each time.
… and how it is implemented
A simple demo program shows that the approach actually works. It employs the DirectX 9.0 API, but porting it to OpenGl probably doesn't require a John Carmack. What's needed is a compliant graphics card, so right now, you have to be lucky enough to own a Ati Radeon 9500/9700 or a nVidia GeForce FX.
In order to keep things as simple as possible, I omitted any elaborate lighting calculations (no lights at all) and shadow volume rendering. The source code basically only shows how to get the data in and out of the floating-point surface.
The vertex and pixel shader mentioned above is called calc.vsh and calc.psh. The program uses another vertex and pixel shader, rnd.vsh and rnd.psh, to actually render the transformed position and a diffuse color to screen.
Details will be probably best understood if you refer to the source code and read the comments there.
Further issues
I consider one of the most serious drawbacks the necessity to lock the floating-point surface, which means effectively retrieving the data from local video memory into system memory, just in order to fill a vertex buffer and send it back. I don't know how to persuade my graphics card to interpret the surface as a vertex buffer (a simple C-style pointer casting doesn't work here), but if you know, please tell me! This cost outweighs eventually the overhead of transforming vertex data multiple times.
Another issue is that with pixel shader version 2.0, only 16 bit precision per color channel is required. As a result, only the first 4 or 5 significant decimal digits of a standard 32 bit float passes the pixel shader unchanged. On the other hand, I'm not sure if this causes a noticeable defect.
Reference
Practical and Robust Stenciled Shadow Volumes for Hardware-Accelerated Rendering
Discuss this article in the forums
Date this article was posted to GameDev.net: 8/17/2003
(Note that this date does not necessarily correspond to the date the article was written)
See Also:
Sweet Snippets
© 1999-2011 Gamedev.net. All rights reserved. Terms of Use Privacy Policy
Comments? Questions? Feedback? Click here!