First Steps To Animation
Preface

You may recall that in the first tutorial "The Basics", we determined that all samples which are built with the Direct3D Framework in the DirectX SDK are created by providing overloaded versions of the CD3DApplication methods:
... ConfirmDevice() OneTimeSceneInit() InitDeviceObjects() FrameMove() Render() DeleteDeviceObjects() FinalCleanup() ...
We also learned the task of every method in the framework class.
In this tutorial we will start to write our first animated app. It will show a red and a yellow object, which can be rotated around its x and y axis. The application uses a Z-Buffer and the simplest keyboard interface I can think of. You can move and rotate the camera with the up, down, left, right, c and the x keys. The input is handled via DirectInput. The movement of the camera feels a little bit like the first X-Wing games. Only a space scanner is missing :-).
This is in response to a lot of e-mails I received. Readers of the first version of this tutorial wanted to know how to rotate and move more than one object in a scene independently.
As always, you can switch between the fullscreen and windowed mode with ALT-F4. F1 will show you the about box. F2 will give you a selection of useable drivers and ESC will shutdown the app.
To compile the source, take a look at The Basics Tutorial. Be sure to also link dinput.lib into the project.
One of the best ways to learn how to use world transformations with Direct3D is the Boids sample from the DirectX 7 SDK. I've found a good tutorial on camera orientation with Direct3DX at Mr. Gamemaker. Other interesting documents on camera orientation are at flipCode, CrystalSpace, Dave's Math Tables and the pages on Geometry from Paul Bourke. In addition, the pages of Mayhem on Matrices and of course the book from John de Goes on Direct3D 3D Game Programming with C++ are useful. For the DirectInput part, I've found Andr� LaMothe's Tricks of the Windows Game Programming Gurus very useful.
The Third Dimension
You need a good familiarity with 3-D geometric principles to program Direct3D applications. The first step in understanding these principles is understanding the transformation pipeline as part of the rendering pipeline:
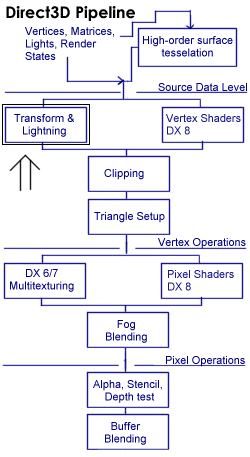
The figure shows the Direct3D pipeline.
The vertex shader unit will be introduced in one of the first tutorials after DirectX 8 is released. In the case of the Geforce2 Graphics Processing Unit, it's a programmable SIMD engine with storage of 192 quadwords of data and 128 app-downloadable instructions, which specify the tasks executed on each vertex. It can do standard transformations, clipping, vertex blending, morphing, animation, skinning, elevation fog, mesh warping, procedural texture coordinate generation such as reflection maps and lighting.
I focus here on the marked T & L Pipeline: You can think of the process of texturing and lighting as an assembly line in a factory, in which untransformed and unlit vertices enter one end, and then several sequential operations are performed on them. At the end of the assembly line, transformed and lit vertices exit. A lot of programmers have implemented their own transformation and lighting algorithms. They can disable parts of this pipeline and send the vertices that are already transformed and lit to Direct3D.
The pixel shader is a compact but powerful programmable pixel processor that runs, in the case of the Geforce 2, as a nine-instruction program on each pixel. It consists of eight register combiners cascaded together, with each taking inputs from up to four textures (which themselves may have been cascaded together), constants, interpolated values and scratch registers.
But in most cases it will be best to use the Direct3D T&L pipeline, because it's really fast, especially with the new T&L graphics drivers, which are provided with the Geforce and Savage 2000 chipsets.
These graphic processors have gained an important role in the last couple of years. Most tasks in the rendering pipeline are now computed by the graphics processing unit:
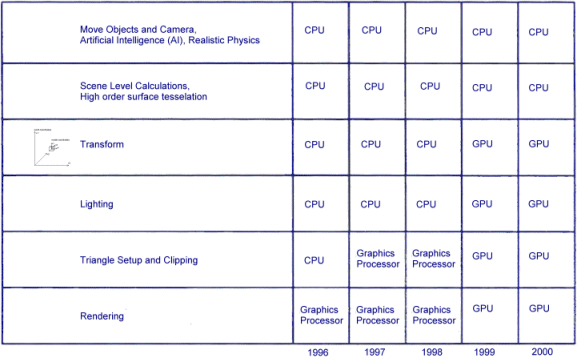
In the old days, transform and lighting functions of the 3D pipeline have been performed by the CPU of the PC. Since 1999, affordable graphic cards with dedicated hardware T&L acceleration have been available. With these cards higher graphics performance is possible, because they can process graphic functions up to four times the speed of the leading CPUs. On the other side, the CPU can now be better utilized for functions such as sophisticated artificial intelligence (AI), realistic physics and more complex game elements. So the new generation of cards will provide a lot of horsepower for the new game generation. It's a great time for game programmers :-)
Transformation Pipeline
It's a complex task to describe and display 3D graphics objects and environments. Describing the 3D data according to different frames of reference or different coodinate systems reduce the complexity. These different frames of reference are called "spaces" such as model space, world space, view space, projection space. Because these spaces use different coordinate systems, 3D data must be converted or "transformed" from one space to another.
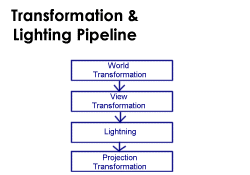
The transformation pipeline transforms each vertex of the object from an abstract, floating-point coordinate space into pixel-based screen space, taking into account the properties of the virtual camera used to render the scene. This transform is done with three transformation matrices: the world-, view- and projection-matrix. The use of world-, view- and projection- transformations ensures that Direct3D only has to deal with one coordinate system per step. Between those steps, the objects are oriented in a uniform manner.
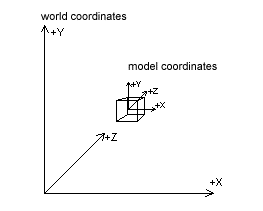
The world transformation stage transforms an object from model or object to world space. Model space is the coordinate space in which an object is defined, independant of other objects and the world itself. In model space, the points of the model or object are rotated, scaled and translated to animate it. For example, think of a Quake 3 model, which rotates his torso and holds his weapon in your direction. With model space it's easier and faster to move an object by simply redefining the transformation from model space to world space than it would be to manually change all the coordinates of the object in world space. For example, to rotate a sphere or cube around its center looks more natural and is much easier when the origin is at the center of the object, regardless of where in world space the object is positioned. Worldspace is the abolute frame of reference for a 3-D world; all object locations and orientations are with respect to worldspace. It provides a coordinate space that all objects share, instead of requiring a unique coordinate system for each object.
To transform the objects from model to world space each object will be rotated about the x-axis, y-axis, or z-axis, scaled (enlarging or shrinking the object) and translated, by moving the object along the x-axis, y-axis, or z-axis to its final orientation, position and size.
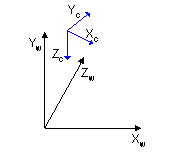
Direct3D uses a left-handed coordinate system, in which every positive axis (x, y or z) is pointing away from the viewer:
The view transformation stage transforms the objects from world space into camera space or view space. This transformation puts the camera at the origin and points it directly down the positive z-axis. The geometry has to be translated in suitable 2D shapes. It's also useful for lighting and backface culling. The light coordinates, which are specified in world space, are transformed into camera space at this stage and the effect of light is calculated and applied to the vertices.
Backface culling happens here. It would be a waste of CPU time to draw the backface of the cube, when it's not visible. To omit drawing the backface is called backface culling. To cull the backface, we need a way to determine the visibility. One of the simplest ways is the following: a front face is one in which vertices are defined in clockwise order. So Direct3D only draws the faces with vertices in clockwise order by default. To modify backface culling, use
// no backface culling
m_pd3dDevice->SetRenderState(D3DRENDERSTATE_CULLMODE, D3DCULL_NONE);When lighting is enabled, as Direct3D rasterizes a scene in the final stage of rendering, it determines the color of each rendered pixel based on a combination of the current material color (and the texels in an associated texture map), the diffuse and specular colors of the vertex, if specified, as well as the color and intensity of light produced by light sources in the scene or the scene's ambient light level.
The projection transformation takes into consideration the camera's horizontal and vertical fields of view, so it applies perspective to the scene. Objects which are close to the front of the frustrum are expanded and objects close to the end are shrunk. It warps the geometry of the frustrum of the camera into a cube shape by setting the passed in 4x4 matrix to a perspective projection matrix built from the field-of-view or viewing frustrum, aspect ratio, near plane or front clipping plane, and far plane or back clipping plane. This makes it easy to clip geometry that lies both inside and outside of the viewing frustrum. You can think of the projection transformation as controlling the camera's internals; it is analogous to choosing a lens for the camera.
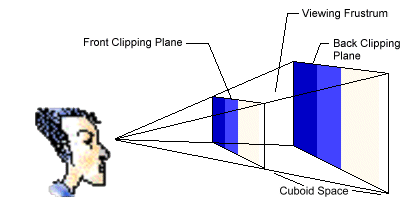
Clipping: the geometry is clipped to the cube shape and the resulting clipped geometry is then transformed into 2D by dropping the z-coordinate and scaling the points to screen coordinates.
Transformation Math
Let's give our old math teachers a smile :-) . I learned math from the beginning-seventies to the mid-eighties at school (yes ... we've got another education system here in Germany). At that time, I never thought that there would be such an interesting use (i.e. game-programming) for it. I wonder if math teachers today talk about the use of math in computer games.
Any impressive game requires correct transformations: Consider the following example. An airplane, let's say an F22, is oriented such that its nose is pointing in the positive z direction, its right wing is pointing in the positive x direction and its cockpit is pointing in the positive y direction. So the F22's local x, y and z axes are aligned with the world x, y and z axes. If this airplane is to be rotated 90 degrees about its y axis, its nose would be pointing toward the world -x axis, its right wing toward the world z axis and its cockpit will remain in the world +y direction. From this new position, rotate the F22 about its z axis. If your transformations are correct, the airplane will rotate about its own z-axis. If your transformations are incorrect, the F22 will rotate about the world z axis. In Direct3D you can guarantee the correct transformation by using 4x4 matrices.
Matrices are rectangular arrays of numbers. A 4x4 world matrix contains 4 vectors, which represent the world space coordinates of the x, y and z unit axis vectors, and the world space coordinate which is the origin of these axis vectors:
x x x 0 y y y 0 z z z 0 x y z 1
Vectors are one of the most important concepts in 3D games. They are mathematical entities that describe a direction and a magnitude (which can, for example, be used for speed). A general purpose vector consists of two coordinates. You can see the direction of these vectors by drawing a line between the two coordinates. Magnitude is the distance between the points.

The first coordinate is called the inital point and the second is the final point. Three dimensional games often use a specific kind of vector - the free vector. Its inital point is assumed to be the origin, and only the final point is specified.
Vectors are usually denoted by a bold face letter of the alphabet, i.e. a. So, we could say the vector v = (1,2,3). The first column is units in the x direction, the second column is units in the y direction, the third column, units in z.
The first column contains the world space coordinates of the local x axis. The second column contains the local y axis and the third column the world space coordinates of the local z axis. The vectors are unit vectors whose magnitude are 1. Basically unit vectors are used to define directions, when magnitude is not really important. The last row contains the world space coordinates of the object's origin, which translates the object.
A special matrix is the identity matrix:
1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1
The identity matrix represents a set of object axes that are aligned with the world axes. The world x coordinate of the local x axis is 1, the world y and z coordinates of the local x axis are 0 and the origin vector is (0, 0, 0). So the local model x axis lies directly on the world x axis. The same is true for the local x and y axes. So it's a "set back to the roots" matrix.
This matrix could be accessed by
D3DMATRIX mat; mat._11 = 1.0f; mat._12 = 0.0f; mat._13 = 0.0f; mat._14 = 0.0f; mat._21 = 0.0f; mat._22 = 1.0f; mat._23 = 0.0f; mat._24 = 0.0f; mat._31 = 0.0f; mat._32 = 0.0f; mat._33 = 1.0f; mat._34 = 0.0f; mat._41 = 0.0f; mat._42 = 0.0f; mat._43 = 0.0f; mat._44 = 1.0f;
If an object's position in model space corresponds to its position in world space, simply set the world transformation matrix to the identity matrix.
A typical transformation operation is a 4x4 matrix multiply operation. A transformation engine multiplies a vector representing 3D data, typically a vertex or a normal vector, by a 4x4 matrix. The result is the transformed vector. This is done with standard linear algebra:
Transform Original Transformed Matrix Vector Vector a b c d x ax + by + cy + dw x' e f g h x y = ex + fy + gz + hw = y' i j k l z ix + jy + kz + lw z' m n o p w mx + ny + oz + pw w'
Before a vector can be transformed, a transform matrix must be constructed. This matrix holds the data to convert vector data to the new coordinate system. Such an interim matrix must be created for each action (scaling, rotation and transformation) that should be performed on the vector. Those matrices are multiplied together to create a single matrix that represents the combined effects of all of those actions (matrix concatenation). This single matrix, called the transform matrix, could be used to transform one vector or one million vectors. The time to set it up amortizes by the ability to re-use it.
One of the pros of using matrix multiplication is that scaling, rotation and translation all take the same amount of time to perform. So the performance of a dedicated transform engine is predictable and consistent. This allows software developers to make informed decisions regarding performance and quality.
Usually the world matrix is a combination of translation, rotation and scaling the matrices of the objects. Code for a translate and rotate world matrix could look like this:
You can make life easy for yourself by storing matrices which contain axis information in each object structure. We're only storing the world matrix here, because the object itself isn't animated, so a model matrix isn't used. A very important thing to remember is that matrix multiplication is not cummutative. That means [a] * [b] != [b] * [a]. The formula for transformation is
where M is the model's matrix, T is the translation matrix and X, Y and Z are the rotation matrices.
The above piece of code translates the object into its place with D3DUtil_SetTranslateMatrix(). Translation can best be described as a linear change in position. This change can be represented by a delta vector [tx, ty, tz], where tx (often called dx) represents the change in the object's x position, ty (or dy) represents the change in its y position, and tz (or dz) the change in its z position. You can find D3DUtil_SetTranslateMatrix() in d3dutil.h. Using our F22 sample from above, if the nose of the airplane is oriented along the object's local z axis, then translating this airplane in the +z direction by using tz will make the airplane move forward in the direction its nose is pointing. The next operation that is performed by our code piece is rotation. Rotation can be described as circular motion about some axis. The incremental angles used to rotate the object here represent rotation from the current orientation. That means, by rotating 1 degree about the z axis, you tell your object to rotate 1 degree about its z axis regardless of its current orientation and regardless on how you got the orientation. This is how the real world operates.
D3DUtil_SetRotateYMatrix() rotates the objects about the y-axis, where fRads equals the amount you want to rotate about this axis. You can find it, like all the other rotation matrices, in d3dutil.h. D3DUtil_SetRotateXMatrix() rotates the objects about the x-axis, where fRads equals the amount you want to rotate about this axis:
D3DUtil_SetRotateZMatrix() rotates the objects about the z-axis, where fRads equals the amount you want to rotate about this axis:
The prototype of D3DMath_MatrixMultiply() prototype looks like VOID D3DMath_MatrixMultiply (D3DMATRIX& q, D3DMATRIX& a, D3DMATRIX& b). In other words: q=a*b. Matrix multiplication is the operation by which one matrix is transformed by another. A matrix multiplication stores the results of the sum of the products of matrix rows and columns. A slow but more understandable matrix multiplication routine could look like this:
A faster version is implemented in d3dutil.h:
Once you've built the world transformation matrix, you need to call the SetTransform() method in the public interface method Render() of the Direct3D Framework. Set the world transformation matrix, specifying the D3DTRANSFORMSTATE_WORLD flag in the first parameter. The view matrix describes the position and the orientation of a viewer in a scene. This is normally the position and orientation of you, looking through the glass of your monitor into the scene. This thinking model is abstracted by a lot of authors by talking about a camera through which you are looking into the scene.
To rotate and translate the viewer or camera in the scene, three vectors are needed. These could be called the LOOK, UP and RIGHT vectors. They define a local set of axes for the camera and will be set at the start of the application in the InitDeviceObjects() or in the FrameMove() method of the framework. The LOOK vector is a vector that describes which way the camera is facing. It's the camera's local z axis. To set the camera's look direction so that it is facing into the screen, we would have to set the LOOK vector to D3DVECTOR (0, 0, 1). The LOOK vector isn't enough to descibe the orientation of the camera. The camera could stand upside down and the LOOK vector won't reflect this change in orientation. The UP vector helps here; it points vertically up relative to the direction the camera points. It's like the camera's y axis. So the UP vector is defined as D3DVECTOR (0, 1, 0). If you turn the camera upside down, the UP vector will be D3DVECTOR (0, -1, 0). We can generate a RIGHT vector from the LOOK and UP vectors by using the cross product of the two vectors. Taking the cross product of any two vectors forms a third vector perpendicular to the plane formed by the first two. The cross product is used to determine which way polygons are facing. It uses two of the polygon's edges to generate a normal. Thus, it can be used to generate a normal to any surface for which you have two vectors that lie within the surface. Unlike the dot product, the cross product is not commutative. a x b = - (b x a). The magnitude of the cross product of a and b, ||axb|| is given by ||a||*||b||*sin(@). The direction of the resultant vector is orthogonal to both a and b. Furthermore, the cross product is used to derive the plane equation for a plane determined by two intersecting vectors. Now imagine, the player is sitting in the cockpit of an F22 instead of looking at it from outside. If the player pushes his foot pedals in his F22 to the left or right, the LOOK and the RIGHT vector has to be rotated about the UP vector (YAW effect) or y axis. If he pushes his flightstick to the right or left, the UP and RIGHT vectors have to be rotated around the LOOK vector (ROLL effect) or z axis. If he pushes the flightstick forward and backward, we have to rotate the LOOK and UP vectors around the RIGHT vector (PITCH effect) or x axis.
There's one problem: when computers handle floating point numbers, little accumulation errors happen whilst doing all this rotation math. After a few rotations these rounding errors make the three vectors un-perpendicular to each other. It's obiously important for the three vectors to stay at right angles from each other. The solution is Base Vector Regeneration. It must be performed before the vectors are rotated around one another. We'll use the following code to handle base vector regeneration:
First, we normalize the LOOK vector, so its length is 1. Vectors with a length of one are called unit or normalized vectors. To calculate a unit vector, divide the vector through its magnitude or length. You can calculate the magnitude of vectors by using the Pythagorean theorem: The length of the vector is retrieved by It's the squareroot of the Pythagorean theorem. The magnitude of a vector has a special symbol in mathematics. It's a capital letter designated with two vertical bars ||A||.
To normalize a vector, the following inline functions in d3dvec.inl are defined:
The Normalize() method divides the vector through its magnitude, which is retrieved by the squareroot of the Pythagorean theorem. sqrt() is a mathematical function from the math library of Visual C/C++ provided by Microsoft™. Other compilers should have a similar function. After normalizing the LOOK vector, we create the RIGHT vector by assigning it the cross product of UP and LOOK vector and normalize it. The UP vector is created out of the cross product of the LOOK and RIGHT vector and a normalization thereafter.
After that, we build the pitch, yaw and roll matrices out of these vectors:
By multiplying, for example, the matYaw matrix with the LOOK and RIGHT vectors, we can rotate two vectors around the other vector.
Now that we set the view matrix: In this matrix u, n and v are the UP, RIGHT and LOOK-direction vectors, and c is the camera's world space position. This matrix contains all the elements needed to translate and rotate vertices from world space to camera space.
The x, y and z translation factors are computed by taking the negative of the dot product between the camera position and the u, v, and n vectors. They are negated because the camera works the opposite to objects in the 3D world.
To rotate the vectors two about another, we change fPitch, fYaw and fRoll variables like this: To synchronize the different number of frame rates with the behaviour of the objects, we have to use a variable with the elapsed time since the last frame. To move the camera forward and backward use the position variable: An interesting transform is the perspective projection, which is used in Direct3D. It converts the camera's viewing frustrum (the pyramid-like shape that defines what the camera can see) into a cube space, as seen above (with a cube shaped geometry, clipping is much easier). Objects close to the camera are enlarged greatly, while objects farther away are enlarged less. Here, parallel lines are generally not parallel after projection. This transformation applies perspective to a 3D scene. It projects 3D geometry into a form that can be viewed on a 2D display.
The projection matrix is set with D3DUtil_SetProjectionMatrix() in d3dutil.cpp. This code sets up a projection matrix, taking the aspect ratio, front (-Q*Zn) or near plane and back or far clipping planes and the field of view with fFOV in radians. Note that the projection matrix is normalized for element [3][4] to be 1.0. This is performed so that w-based range fog will work correctly. After this last transform, the geometry must be clipped to the cube space and converted from homogenous coordinates to screen coordinates by dividing the x-, y- and z-coordinates of each point by w. Direct3D performs these steps internally. Homogenous coordinates: Just think of a 3x3 matrix. As you've learned above, in a 4x4 matrix, the first three elements, let's say i,j and k, in the fourth row are needed to translate the object. With 3x3 matrices an object cannot be translated without changing its orientation. If you add some vector (representing translation) to the i, j and k vectors, their orientation will also change. So we need fourth dimension with the so called homogenous coordinates.
The sample uses (as usual in this series) the Direct3D Framework. The application class in animated objects.cpp looks like: The objects are described by vertices in m_pvObjectVertices[16] and by indices in m_pwObjectIndices[30]. There's an object structure called object. The fps-independant movement is guaranteed by the two time variables, which holds the start and the elapsed time between two frames. As usual ConfirmDevice() is called as the first framework method, but it's not used here, because we won't need any special capabilities of the graphics card. The other framework methods are called top - down and will be mentioned in this order in the following paragraphs. The OneTimeSceneInit() function performs basically any one-time resource allocation and is invoked once per application execution cycle. Here it contains the code to construct the two objects: The sample project shows a simple object. Well... a cube would bore you. The wireframe model shows the polygons and points of the object.
Point #1 is m_pvObjectVertices[0] and m_pvObjectVertices[5], point #2 is m_pvObjectVertices[1] and m_pvObjectVertices[6], point #3 is m_pvObjectVertices[3] and m_pvObjectVertices[11], etc.
Every point is declared as a vector with D3DVECTOR. For every face of the object a normal is defined, so that there are nine normals. The normal vector is used in Gouraud shading mode, to control lighting and do some texturing effects. Direct3D applications do not need to specify face normals; the system calculates them automatically when they are needed. The normal vectors are normalized with a call to The Normalize() method divides the vector through its magnitude, which is retrieved by the square root of the Pythagorean theorem. The last two variables of D3DVERTEX are the texture coordinates. Most textures, like bitmaps, are a two dimensional array of color values. The individual color values are called texture elements, or texels. Each texel has a unique address in the texture: its texel coordinate. Direct3D programs specify texel coordinates in terms of u,v values, much like 2-D Cartesian coordinates are specified in terms of x,y coordinates. The address can be thought of as a column and row number. However, in order to map texels onto primitives, Direct3D requires a uniform address range for all texels in all textures. Therefore, it uses a generic addressing scheme in which all texel addresses are in the range of 0.0 to 1.0 inclusive. Direct3D maps texels in texture space directly to pixels in screen space. The screen space is a frame of reference in which coordinates are related directly to 2-D locations in the frame buffer, to be displayed on a monitor or other viewing device. Projection space coordinates are converted to screen space coordinates, using a transformation matrix created from the viewport parameters. This sampling process is called texture filtering. There are four texture filtering methods supported by Direct3D: Nearest Point Sampling, Linear Texture Filtering, Anisotropic Texture Filtering, Texture Filtering With Mipmaps. We're not using a texture here, so more on texture mapping in Tutorial #3 "Multitexturing".
Now on to the next part of the OneTimeSceneInit() method: This piece of code generates the indices for the D3DPT_TRIANGLELIST call in DrawIndexedPrimitive(). Direct3D allows you to define your polygons on one of two ways: By defining their vertices or by defining indices into a list of vertices. The latter approach is usually faster and more flexible, because it allows objects with multiple polygons to share vertex data. The object consists of only seven points, which are used by 15 vertices.
There are two ways of grouping the vertices that define a primitive: using non-indexed primitives and using indexed primitves. To create a nonindexed primitive, you fill an array with an ordered list of vertices. Ordered means that the order of the vertices in the array indicates how to build the triangles. The first triangle consists of the first three vertices, the second triangle consists of the next three vertices and so on. If you have two triangles that are connected, you'll have to specify the same vertices multiple times. To create an indexed primitive, you fill an array with an unordered list of vertices and specify the order with a second array (index array). This means that vertices can be shared by multiple triangles, simply by having multiple entries in the index array refer to the same vertex. Most 3D models share a number of vertices. Therefore, you can save bandwith and CPU time sharing these vertices among multiple triangles.
In OneTimeSceneInit() the two objects are defined with the help of the m_pObjects structure.
To position the first object on the screen, a location has to be chosen. The yellow object should be located on the left and the red one on the right side. The colors for the material properties are chosen in the r, g and b variables. They are set later in the framework function Render() with a call to The InitDeviceObjects() is used to initialize per-device objects such as loading texture bits onto a device surface, setting matrices and populating vertex buffers. First, we'll use it here to set a material. When lighting is enabled, as Direct3D rasterizes a scene in the final stage of rendering, it determines the color of each rendered pixel based on a combination of the current material color (and the texels in an associated texture map), the diffuse and specular colors at the vertex, if specified, as well as the color and intensity of light produced by light sources in the scene or the scene's ambient light level.
You must use materials to render a scene if you are letting Direct3D handle lighting.
By default, no material is selected. When no material is selected, the Direct3D lighting engine is disabled.
D3DUtil_InitMaterial() sets the RGBA values of the material. Color values of materials represent how much of a given light component is reflected by a surface that is rendered with that material. A material's properties include diffuse reflection, ambient reflection, light emission and specular hightlighting:
A material whose color components are R: 1.0, G: 1.0, B: 1.0, A: 1.0 will reflect all the light that comes its way. Likewise, a material with R: 0.0, G: 1.0, B: 0.0, A: 1.0 will reflect all of the green light that is directed at it. SetMaterial() sets the material properties for the device.
After setting the material, we can setup the light. Color values for light sources represent the amount of a particular light component it emits. Lights don't use an alpha component, so you only need to think about the red, green, and blue components of the color. You can visualize the three components as the red, green, and blue lenses on a projection television. Each lens might be off (a 0.0 value in the appropriate member), it might be as bright as possible (a 1.0 value), or some level in between. The colors coming from each lens combine to make the light's final color. A combination like R: 1.0, G: 1.0, B: 1.0 creates a white light, where R: 0.0, G: 0.0, B: 0.0 results in a light that doesn't emit light at all. You can make a light that emits only one component, resulting in a purely red, green, or blue light, or the light could use combinations to emit colors like yellow or purple. You can even set negative color component values to create a "dark light" that actually removes light from a scene. Or, you might set the components to some value larger than 1.0 to create an extremely bright light. Direct3D employs three types of lights: point lights, spotlights, and directional lights.
You choose the type of light you want when you create a set of light properties. The illumination properties and the resulting computational overhead varies with each type of light source. The following types of light sources are supported by Direct3D 7: DirectX 7.0 does not use the parallel-point light type offered in previous releases of DirectX. Tip: You should avoid spotlights, because there are more realistic ways of creating spotlights than the default method supplied by Direct3D: Such as texture blending: see the "Multitexturing" tutorials. The sample sets up an ambient light and, if the graphic card supports it, two directional lights. An ambient light is effectively everywhere in a scene. It's a general level of light that fills an entire scene, regardless of the objects and their locations within that scene. Ambient light is everywhere and has no direction or position. There's only color and intensity. SetRenderState() sets the ambient light by specifying D3DRENDERSTATE_AMBIENT as the dwRenderStateType parameter, and the desired RGBA color as the dwRenderState parameter. Keep in mind that the color values of the material represent how much of a given light component is reflected by a surface. So the light properties are not the only properties which are responsible for the color of the object you will see.
Additionally there are up to two directional lights used by the sample. Although we use directional lights and an ambient light to illuminate the objects in the scene, they are independent of one another. Directional light always has direction and color, and it is a factor for shading algorithms, such as Gouraud shading. It is equivalent to use a point light source at an infinite distance.
The sample first checks the capabilities of the graphics device. If it supports directional light, the light will be set by a call to the SetLight() method, which uses the D3DLIGHT7 structure. The position, range, and attenuation properties are used to define a light's location in world space, and how the light behaves over distance. The D3DUtil_InitLight() method in d3dutil.cpp sets a few default values. Only the light position is set explicitly for the first light. The light position is described using a D3DVECTOR with the x-, y- and z-coordinates in world space. The first light is located under the objects and the second light is located above these. The second light is only set if the graphics device supports it. It's a bit darker.
Directional lights don't use range and attentuation variables. A light's range property determines the distance, in world space, at which meshes in a scene no longer receive light. So the dvRange floating point value represents the light's maximum range. The attentuation variables controls how a light's intensity decreases toward the maximum distance, specified by the range property. There are three attentuation values, controlling a light's constant, linear and quadratic attentuation with floating point variables. Many applications set the dvAttentuation1 member to 1.0f and the others to 0.0f. Beneath the material and lights, the InitDeviceObjects() method sets the projection matrix and aspect ratio of the viewport.
The FrameMove() method handles most of the keyboard input and the matrix stuff. All the rotations and translations for the objects and the camera are set in this method.
At first you need a small DirectInput primer to understand all the input stuff presented in this method. With DirectInput, which is the input component of DirectX, you can access keyboard, mouse, joystick and all other forms of input devices in a uniform manner. Although DirectInput can be extremely complex if you use all its functionality, it can be quite manageable at the lowest level of functionality, which we will use here.
DirectInput consists of run-time DLLs and two compile-time files: dinput.lib and dinput.h. They import the library and the header. Using DirectInput is straightforward: Setup DirectInput: Getting Input: DirectInput can send you immediate mode state information or buffer input, time-stamped in a message format. We'll only use the immediate mode of data acquisition here (see the DirectX SDK documentation for information on buffered mode). We call DirectInputCreateEx() in the CreateDInput() method. It's called in WinMain() with To retrieve the instance of the sample, we use GetWindowLong( hWnd, GWL_HINSTANCE ). The constant DIRECTINPUT_VERSION determines which version of DirectInput your code is designed for. The next parameter is the desired DirectInput Interface, which should be used by the sample. Acceptable values are IID_IDirectInput, IID_IDirectInput2 and IID_IDirectInput7. For backward compatibility you can define an older verison of DirectInput there. This is useful, for example, for WinNT which supports only DirectX 3. The last parameter holds the DirectInput interface pointer. To create one input device - the keyboard - we use CreateDeviceEx() in CreateInputDevice() It's called in WinMain() with Besides creating the input device it sets the data format of the keyboard with SetDataFormat() and the cooperative level with SetCooperativeLevel(). The first parameter of CreateDeviceEx() is the GUID (Globally Unique Indentifier), that identifies the device you want to create. You have to enumerate devices with EnumDevices() to get the GUIDs for any weird stuff like joysticks, flightsticks, virtual reality helms and suits. You won't need to perform an enumeration process for the keyboard, because all computers are required to have one and won't boot without it. So the GUID for keyboards is predefined by DirectInput. The next parameter is for the desired interface. Accepted values are currently IID_DirectInputDevice, IID_DirectInputDevice2 and IID_DirectInputDevice7. CreateDeviceEx() returns the interface pointer pDIdDevice which will be stored later in g_Keyboard_pdidDevice2.
By setting the Data format with SetDataFormat(), you tell DirectInput how you want the data from the device to be formatted and represented. You can define your own DIDATAFORMAT structure, or you can use one of the predefined global constants: c_dfDIKeyboard is the constant for the keyboard. Generally you won't need to define a custom structure, because the predefined ones will allow your application to use most of the off-the-shelf devices.
The next step you need to perform before you can access the DirectInput device (in this case the keyboard) is to use the method SetCooperativeLevel() to set the device's behaviour. It determines how the input from the device is shared with other applications. For a keyboard you have to use the DISCL_NONEXCLUSIVE flag, because DirectInput doesn't support exclusive access to keyboard devices. Even Ctrl+Alt+Esc wouldn't work with an exclusive keyboard. DISCL_FOREGROUND restricts the use of DirectInput on the foreground. The device is automatically unaquired when the associated window moves to the background. Whereas DISCL_BACKGROUND gives your app the possiblity to use a DirectInputDevice in fore- and background. In addition, this method needs the handle of the window, to set the exclusivity. To get the keyboard input, we call, in the FrameMove() method, the following functions:
The array disks[256] holds the keyboard states. To get access to the DirectInput Device, you have to acquire it. You retrieve the keyboard states with GetDeviceState(). The values are used with To test if any key is down, you must test the 0x80 bit in the 8-bit byte of the key in question; in other words the uppermost bit.
At the end of the sample, the DirectInput device is released with a call to That's all with DirectInput. Now back to graphics programming. FrameMove() uses a timing code to ensure that all the objects and the camera move/rotate in the same speed at every possible fps. To calculate the elapsed time, you have to subtract m_fStartTimeKey from fTimeKey. To rotate the yellow object about its x- and z- axis, we have to change the variables fRoll and fPitch in the m_pObject structure. They are used in the following translate and rotate matrix methods. As described above, the method D3DUtil_SetTranslateMatrix() would translate the yellow object into its place and D3DUtil_SetRotateXMatrix() and D3DUtil_SetRotateZMatrix() would rotate it around the x-axis and z-axis. We won't use D3DUtil_SetRotateYMatrix() here. They are useful for the upcoming tutorials. At last, the position of the yellow object in the world matrix will be stored in the m_pObjects structure.
The same functionality lies behind the code for the red object. The only differences are the use of other keys and the storage of the variables in another object struture.
After translating the objects, the camera has to be placed and pointed in the right direction. The vLook, vUp, vRight and vPos vectors are holding the position and the LOOK, UP and RIGHT vectors of the camera. The LOOK vector points in the direction of the positive z-axis. The UP vector points into the direction of the positive y-axis and the RIGHT vector points in the direction of the positive x-axis. The variables fPitch, fYaw and fRoll are responsible for the orientation of the camera. The camera is moved back and forward with vPos, whereas speed holds the back and forward speed of it.
The three orientation vectors are normalized with Base Vector Regeneration, by normalizing the LOOK vector, building a perpendicular vector out of the UP and LOOK vector, normalizing the RIGHT vector and building the perpendicular vector of the LOOK and RIGHT vector, the UP vector. Then the UP vector is normalized.
Normalization produces a vector with a magnitude of 1. The cross product method produces a vector, which is perpendicular to the two vectors provided as variables.
The rotation matrices are built with D3DUtil_SetRotationMatrix() and executed with D3DUtil_MatrixMultiply().
The Render() method is called once per frame and is the entry point for 3d rendering. It clears the viewport, and renders the two objects with proper material. We are using a Z-Buffer here by calling in InitDeviceObjects() and clearing the z-buffer with Clear() shown above. That's not a big thing ... is it? But z-buffers play an important role in task of visible surface determination. Switch it off and you'll see what I mean. Polygons closer to the camera must obscure polygons which are farther away. There are a number of solutions for this task, for example drawing all the polygons back to front, which is slow and not supported by most hardware, Binary Space Partition trees, Octrees and so on. Direct3D supports the creation of a DirectDraw surface that stores depth information for every pixel on the display. Before displaying your virtual world, Direct3D clears every pixel on this depth buffer to the farthest possible depth value. Then when rasterizing, Direct3D determines the depth of each pixel on the polygon. Is a pixel closer to the camera than the one previously stored in the depth buffer, the pixel is displayed and the new depth value is stored in the depth buffer. This process will continue until all pixels are drawn.
There's not only a z-buffer, but there's also a w-buffer. Think of the w-buffer as a higher quality z-buffer, which isn't supported in hardware as often as z-buffers. It reduces problems exhibited in z-buffers with objects at a distance and has a constant performance for both near and far objects. You only have to replace TRUE in the SetRenderState() call through D3DZB_USEW to use it.
As usual the Render() method uses the BeginScene()/EndScene() pair. The first function is called before performing rendering, the second after that. BeginScene causes the system to check its internal data structures, the availability and validity of rendering surfaces, and sets an internal flag to signal that a scene is in progress. Attempts to call rendering methods when a scene is not in progress fail, returning D3DERR_SCENE_NOT_IN_SCENE. Once your rendering is complete, you need to call EndScene(). It clears the internal flag that indicates that a scene is in progress, flushes the cached data and makes sure the rendering surfaces are OK.
The second parameter of DrawIndexedPrimitive(), D3DFVF_VERTEX, describes the vertex format used for this set of primitives. The d3dtypes.h header file declares these flags to explicitly describe a vertex format and provides helper macros that act as common combinations of such flags. Each of the rendering methods of IDirect3Ddevice7 accepts a combination of these flags, and uses them to determine how to render primitives. Basically, these flags tell the system which vertex components—position, normal, colors, and the number of texture coordinates–your application uses and, indirectly, which parts of the rendering pipeline you want Direct3D to apply to them. In addition, the presence or absence of a particular vertex format flag communicates to the system which vertex component fields are present in memory, and which you've omitted. By using only the needed vertex components, your application can conserve memory and minimize the processing bandwidth required to render models. D3DFVF_XYZ includes the position of an untransformed vertex. You have to specify a vertex normal, a vertex color component (D3DFVF_DIFFUSE or D3DFVF_SPECULAR), or include at least one set of texture coordinates (D3DFVF_TEX1 through D3DFVF_TEX8). D3DFVF_NORMAL shows that the vertex format includes a vertex normal vector and D3DFVF_TEX1 shows us the number of texture coordinate sets for this vertex. Here it's one texture coordinate set.
The unlit and untransformed vertex format is equivalent to the older pre DirectX 6 structure D3DVERTEX: This method is not used here. It's empty. We're destroying the DirectInput device here. You should use this method in DeleteDeviceObjects(), because if you switch, for example, from windowed to fullscreen mode, the device would be destroyed every time.
I hope you enjoyed our small trip into the world of the Direct3D 7 IM Framework and transformation. This will be a work in progress in the future. If you find any mistakes or if you have any good ideas to improve this tutorial or if you dislike or like it, give me a sign at wolf@direct3d.net.
© 1999-2000 Wolfgang Engel, Mainz, Germany Discuss this article in the forums
See Also: © 1999-2011 Gamedev.net. All rights reserved. Terms of Use Privacy Policy
The World Matrix
m._41 = tx; m._42 = ty; m._43 = tz;
}
=
1 0 0 0
0 1 0 0
0 0 1 0
tx ty tz 1
The View Matrix



The Projection Matrix
In this 4D space, every point has a fourth component that measures distance along an imaginary fourth-dimensional axis called w. To convert a 4D point into a 3D point, you have to divide each component x, y, z and w by w. So every multiplication of a point whose w component is equal to 1 represent that same point. For example (4, 2, 8, 2) represents the same point as (2, 1, 4, 1).
To describe distance on the w-axis, we need another vector l. It points in the positive direction of the w-axis and its neutral magnitude is 1, like the other vectors.
In Direct3D, the points remain homogenous, even after being sent through the geometry pipeline. Only after clipping, when the geometry is ready to be displayed, are these points converted into Cartesian coordinates by dividing each component by w.
Before doing the transformation stuff, normally the viewport is set by the Direct3D IM Framework. It defines how the horizontal, vertical and depth components of a polygon's coordinates in cube space will be scaled before the polygon is displayed.Down to the Code
OneTimeSceneInit()


Defining indices into a list of vertices has one disadvantage: the cost of memory. There could be problems with sharing vertices of a cube. Lighting a cube is done by using its face normals, which is perpendicular to the face's plane. If the vertices of a cube are shared, there's only one shared vertex for two triangles. This shared vertex has only one normal to calculate the face normal, so the lighting effect wouldn't be what you want.InitDeviceObjects()
FrameMove()
IID_IDirectInputDevice2,
(VOID**)&pDIdDevice, NULL ) ) )
return 0;
// Set the device data format
if( FAILED( pDIdDevice->SetDataFormat( pdidDataFormat ) ) )
return 0;
// Set the cooperativity level
if( FAILED( pDIdDevice->SetCooperativeLevel( hWnd, dwFlags ) ) )
return 0;
if(guidDevice == GUID_SysKeyboard)
g_Keyboard_pdidDevice2 = pDIdDevice;
return S_OK;
}
Render()
DeleteDeviceObjects()
FinalCleanup()
Finale
Date this article was posted to GameDev.net: 1/10/2000
(Note that this date does not necessarily correspond to the date the article was written)
Direct3D
Comments? Questions? Feedback? Click here!