3. Concept of Design
3.1 A core::tree<> must be concretely constructed
Although this point is probably well understood, it bears mentioning here. Following the notion all STL containers follow, the core::tree<> container must be concretely constructed to exist. Nothing fancy is going on here, but this is an important clarification to ensure the concepts of the core::tree<> are clearly understood.
As stated in Knuth's definition of trees, there is one specially designated node of the tree called the root. While each subtree has its own root, only one root node exists for the tree in its entirety – the root for the entire tree. Conceptually, root node of the entire tree is the initial core::tree<> object. Therefore, for all uses of core::tree<> and core::tree<>::iterator, at least one core::tree<> object must be concretely constructed.
To concretely construct a core::tree<>, you might do the following:
core::tree<int> t;
In the above code sample, t is the root node of the entire tree and is a concrete core::tree<int> object. All modifications made through iterators based off of t are stored within the core::tree<> t. When t is destroyed, the entire tree t contains is destroyed. This is identical to the behavior of STL containers [5].
The point being made here may seem overly obvious (and that's good if it is), but it bears mentioning. The reasoning is, the core::tree<> and the core::tree<>::iterator are mostly interchangeable. However, simply constructing a core::tree<>::iterator will not create a core::tree<>. Additionally, each time a core::tree<> is concretely constructed, an entire tree is created.
That being said, each time a core::tree<>::iterator is constructed, nothing more than your typical iterator is constructed. When it is destructed, only the iterator (not the tree it points to) is destroyed.
3.2 Understanding the core::tree<> recursive characteristic
The recursive characteristic of trees is important to conceptualize when working with trees or understanding any generic framework or algorithm for trees [6] (i.e. the core::tree<> framework). A child node of one tree may be the parent node of another tree. While there is always one root node for the entire tree (as explained in section 3.1), a tree can have any number of children nodes. Each of these children nodes are root nodes to the subtrees they create.
Therefore, the role of a node in a tree changes depending on how it is viewed. In one case, a node may be a child node for a parent, merely existing to be iterated over for the larger container it resides in. Yet, in another case, the same node may be a parent node for several children, now acting as the container of perhaps, many children nodes.
This brings us to a fundamental rule for trees, which paraphrases Knuth's definition of trees:
All branches within a tree are trees themselves [7].
It is from this understanding that the core::tree<> implementation was designed, instinctively following Knuth's recursive tree definition and the notion of self-similarity (the concept that some "things" are made up of pieces that are similar to the "thing" they are making up, for example, trees) common in the field of chaos [7].
The following two concepts are fundamental to understanding the design of the core::tree<> family:
a core::tree<> is a core::tree<>::iterator
a core::tree<>::iterator is a core::tree<>
In both cases (trees as iterators and iterators as trees), it is important to understand that; 1) when given a core::tree<>, you also are given a core::tree<>::iterator – as any tree is also a node of a tree and 2) when given a core::tree<>::iterator, you are also given a core::tree<> – as any node within a tree is also a tree, itself.
The following two sections breakdown the above two concepts; 3.3) trees as iterators and 3.4) iterators as trees. A great deal of detail is spent clarifying these concepts as they are building blocks of the core::tree<> functionality.
3.3 A core::tree<> is core::tree<>::iterator
Each node within a tree is a tree itself. This follows Knuth's definition of trees. However, each node within a tree is just that as well, a node. Therefore, any level of a tree can be thought of as 1) a single-level store of trees and 2) a single-level store of nodes. For example, consider the following tree in Figure 3.1:

Figure 3.1: Isolating a single-level of a tree
In the green highlighted section of Figure 3.1, two nodes (b and c) are identified as children of node a. While b and c are subtrees themselves (i.e. containers), they must also be accessible from their containing parent. In order to first conceptualize this, consider b and c outside of the context of a tree and instead, in a single-level container.
If b and c were contained in a single-level (outside of a tree), they might look something like this:
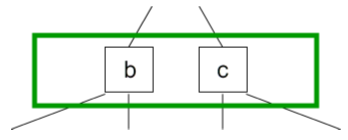
Figure 3.2: Single-level view of a tree
Figure 3.2 shows how b and c would be contained by themselves outside of the context of a tree. Given this context, b and c could be wrapped in single-level container. For example, b and c could be stored within an std::set:
std::set<char> s;
s.insert('b');
s.insert('c');
To iterate through the single-level set, the following could be done:
for (std::set<char>::iterator iter = s.begin(); iter != s.end(); ++iter)
{
std::cout << *iter << std::endl;
}
In this case, an std::set<char>::iterator iter is used to move through the set elements one at a time. Thus, using the std::set<> example as a base concept of how a node can be iterated through in any single-level container, the same functionality must also be reproduced from the tree container – in other words, the core::tree<> must allow each node to be acted on as an iterator. Thankfully, it does this quite naturally.
Reproducing the same behavior as the single-level std::set<> with the core::tree<> is simple:
core::tree<char> t;
t.insert('b');
t.insert('c');
for (core::tree<char>::iterator iter = t.begin(); iter != t.end(); ++iter)
{
std::cout << *iter << std::endl;
}
With the exception of changing the container type and variable name, all other pieces of functionality are exactly the same in the tree implementation as in the set implementation. However, the underlying storage mechanism between the std::set<> and the core::tree<> are largely different. Each node within the std::set<> is simply a node. Each node within the core::tree<> is not only a node, but also a fully functional tree, with all the properties and functionality of the core::tree<> container. Given that context, each node of the core::tree<> must not only be a fully functioning tree, it must also be able to be acted upon as an iterator.
In summary, the above demonstrates why a core::tree<> must be a core::tree<>::iterator (as explained in the std::set<> coding example) and how they achieve this goal (as explained in the core::tree<> coding example). As stated initially, each node within the tree is a tree itself (including all the functionality of a tree), but also has all the functionality of an iterator. This is functionally important as without it, it would be impossible to iterate through a core::tree<> without the root core::tree<> container being passed to any piece of code that uses it.
3.4 A core::tree<>::iterator is a core::tree<>
To demonstrate the necessity of a core::tree<>::iterator behaving as a core::tree<> the tree example in section 3.3 can be built upon. To begin, it is necessary to first revisit the code in the previous section:
core::tree<char> t;
t.insert('b');
t.insert('c');
In the above code snippet, the tree t is concretely constructed and has two children inserted into it. According to the above code, the following tree is built:
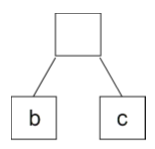
Figure 3.3: b-c tree
Notice how the label is not present in the root node tree in Figure 3.3. The missing label can be fixed easily enough, it was simply not labeled before. The following code corrects the missing label issue (and includes all the code to rebuild the tree, include nodes: a, b and c):
core::tree<char> t;
*t = 'a'; // or t.data('a');
t.insert('b');
t.insert('c');
The following tree is now being built with a, b, and c clearly labeled (as seen in Figure 3.4):
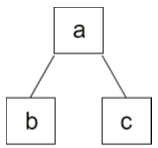
Figure 3.4: a-b-c tree
To continue building the next level of the tree (beyond b and c), iterators of the core::tree<> are needed to access the deeper levels of the tree, as the nodes beyond b and c cannot be inserted directly from the core::tree<char> t (inserts, push_backs, push_fronts can only insert to the level directly underneath them).
Figure 3.5 shows the tree nodes currently built outlined in blue and the tree nodes not yet built outlined in green:
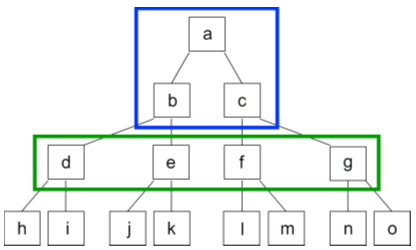
Figure 3.5: Building nodes: d, e, f and g
To insert nodes d, e, f and g, access to nodes b and c are first needed. This access is needed so insertion functionality can be called from b and c to insert their children. Nodes d and e can be inserted once access to node b is obtained. Nodes f and g can be inserted once access to node c is obtained.
Initially, the work to insert nodes d, e, f and g must be done with only the tree t (which is the 'a' node in figure 3.5), as only tree t is immediately available. From the core::tree<> t, search functionality can be called – single-level search functionality (i.e. find()) or multi-level search functionality (i.e. tree_find_depth(), tree_find_breadth()) – all of which return iterators to elements found from their search results. Since it is known that nodes b and c are one level below the tree's root node, a single-level find() can be used for gaining access to them.
Once the tree iterators (to nodes b and c) are obtained from the single-level find results of tree t, they can be used as tree containers and the remaining d, e, f
and g nodes can be inserted into their subtrees.
It is important to note that while most of the work will be done with iterators, the insert functionality that will be performed is actually tree container functionality, not tree iterator functionality. An iterator is just a wrapper for an element that knows its location within a container. A container, on the other hand, is the store that holds those elements accessed by iterators. When dealing with the core::tree<> much of the functionality used within the iterator is actually container-based functionality, not iterator-based functionality.
The following code includes the initial tree building (a, b and c) and further contains the code required to insert nodes; d, e, f and g:
core::tree<char> t;
*t = 'a';
t.insert('b');
t.insert('c');
core::tree<char>::iterator iter;
// find the 'b' node
iter = t.find('b');
// insert nodes d and e inside the b tree
iter.insert('d');
iter.insert('e');
// find the 'c' node
iter = t.find('c');
// insert nodes f and g inside the c tree
iter.insert('f');
iter.insert('g');
With the above code, nodes d, e, f and g are inserted into their correct locations within the tree. As stated previously, the majority of the work done (total lines of code) is performed by tree iterators. However, 67% of the work done by the tree iterators is tree container-based functionality (4 of the 6 iterator calls highlighted in blue are 'inserts' – i.e. container functionality). Thus, the tree iterator is acting more like a tree container, than as a tree iterator.
To further drive home the point of tree iterators acting as tree containers, a closer look can be taken on how to output the tree generated by the previous code snippet. One way to perform that is through the following code:
std::cout << *t << std::endl;
for (iter = t.begin(); iter != t.end(); ++iter)
{
std::cout << *iter << std::endl;
for (core::tree<char>::iterator inner = iter.begin(); inner != iter.end(); ++inner)
{
std::cout << "\t" << *inner << std::endl;
}
}
Again, as seen from above, even in cases where the tree iterator is strongly performing tree iterator functionality, it is necessary for it to behave as a tree container. In the above code snippet, the two blue highlighted uses of iter (iter.begin() and iter.end()) are uses where the tree iterator is being called upon to perform tree container actions (begin() returns the first element of the tree, end() returns the last element of the tree).
In summary, scenarios have been shown where tree construction was only possible through first iterating to that point and then using that iterator to perform tree container functionality (as in the d, e, f, g code snippet). Additionally, a case has been shown where even performing highly iterator based functionality, tree iterators are required to act as tree containers to complete their assigned task (as in the above tree output code snippet).
Through the above two code snippets, it should be clear why tree iterators must act as tree containers and additionally, how these tree iterators perform their required tree container actions in a rather seamless manner.

Subtleties of the core::tree<>
|